
Fala pessoal!
Nesse artigo eu gostaria de compartilhar uma situação que costuma ocorrer de vez em quando no meu dia a dia de consultor, atendendo vários clientes e ambientes diferentes, e que na sexta-feira voltou a ocorrer, que é quando existem “coisas estranhas” em strings e tabelas (uma alusão ao seriado “Stranger Things”), que é a ocorrência de caracteres não visíveis.
Após ajudar um consultor a identificar e resolver isso, pensei em criar uma solução prática de resolver isso de forma mais rápida nas próximas vezes e também ajudar outras pessoas que possam ter esse problema no seu dia a dia, o que é costuma ocorrer especialmente em ambientes que acabaram de passar por migração ou trabalham com importação de dados de vários sistemas, API’s ou arquivos.
Simulando o problema
Para demonstrar a vocês esse problema acontecendo, vou criar uma tabela bem simples, e preencher essa tabela com valores aleatórios e uma linha fixa que vou inserir. Para isso, vou utilizar uma função para gerar valores aleatórios, que é a fncRand, especialmente útil para utilizar em funções:
|
1 2 3 4 5 6 7 8 9 |
CREATE FUNCTION dbo.fncRand( @Numero BIGINT ) RETURNS BIGINT AS BEGIN RETURN (ABS(CHECKSUM(PWDENCRYPT(N''))) / 2147483647.0) * @Numero END GO |
Com essa função, vou criar a tabela e inserir alguns valores aleatórios:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
IF (OBJECT_ID('tempdb..#Teste') IS NOT NULL) DROP TABLE #Teste CREATE TABLE #Teste ( Id INT IDENTITY(1,1) NOT NULL PRIMARY KEY, Nome VARCHAR(100) NOT NULL ) DECLARE @Contador INT = 1, @Total INT = 100, @Contador2 INT = 1, @Total2 INT = 10, @String VARCHAR(100) WHILE(@Contador <= @Total) BEGIN SET @Contador2 = 1 SET @String = '' WHILE(@Contador2 <= @Total2) BEGIN IF (@Contador2 <= 8) SET @String += CHAR(65 + dbo.fncRand(25)) ELSE SET @String += CHAR(dbo.fncRand(255)) SET @Contador2 += 1 END INSERT INTO #Teste VALUES(@String) SET @Contador += 1 END |
Exemplo da tabela gerada:
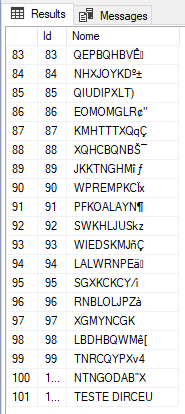
Agora que criamos a tabela, vou demonstrar o que o cliente estava tentando fazer, não conseguiu e nos acionou para ajudar a entender o que estava acontecendo:
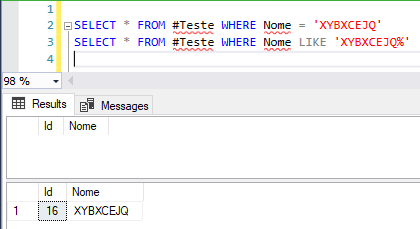
Ué.. A consulta de igualdade não retornou nada, só a utilizando o operador LIKE. Copiei e colei a string retornada pela consulta do LIKE e mesmo assim não funcionou.. O que está acontecendo ?
Identificando o problema de caracteres ocultos
Bom, provavelmente devem ter caracteres ocultos no meio da string.. Uma forma bem rápida de descobrir isso é contar a quantidade de caracteres da string e analisar quantos caracteres conseguimos visualizar:

Conforme o print acima, eu consigo visualizar 8 caracteres, mas a string possui 10, de acordo com as funções LEN e DATALENGTH, o que provavelmente indica que temos caracteres “invisíveis” na nossa coluna ou string, que podem ser os caracteres de controle da tabela ASCII (lembrando que a tabela varia de acordo com o idioma e o collation):
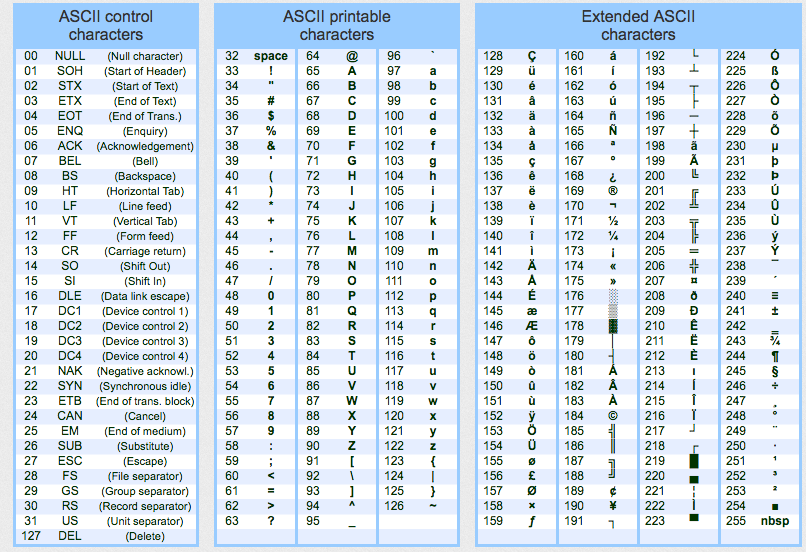
Para ajudar nessa identificação, criei a função abaixo que nos ajudará a identificar as linhas que possuem esses caracteres de controle:
|
1 2 3 4 5 6 7 8 |
CREATE FUNCTION [dbo].[fncPossui_Caractere_Oculto]( @String VARCHAR(MAX) ) RETURNS BIT AS BEGIN RETURN (CASE WHEN PATINDEX('%[^ !"#$%&''()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ\^_`abcdefghijklmnopqrstuvwxyz|{}~€‚ƒ„…†‡ˆ‰Š‹ŒŽ‘’“”•–—˜™š›œžŸ¡¢£¤¥¦§¨©ª«¬®¯°±²³´µ¶·¸¹º»¼½¾¿ÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖ×ØÙÚÛÜÝÞßàáâãäåæçèéêëìíîïðñòóôõö÷øùúûüýþÿ[[]%', REPLACE(@String, ']', '')) > 0 THEN 1 ELSE 0 END) END |
A sua utilização é bem simples, e retorna os registros que possuem caracteres “não visíveis”:
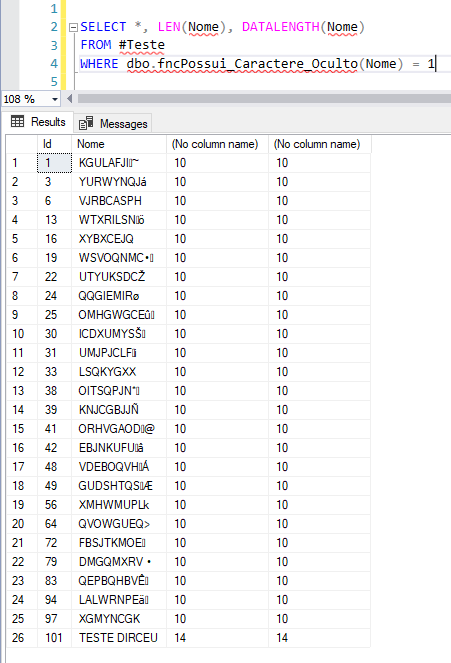
Identificando quais são os caracteres ocultos
Precisamos agora identificar quais são esses caracteres ocultos para avaliar se vamos tentar substituí-los ou não. Para facilitar essa tarefa, criei a função fncMostra_Caracteres_Ocultos, que vai receber a string original e retornar a posição e qual o código ASCII de cada caracter oculto na string:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
CREATE FUNCTION [dbo].[fncMostra_Caracteres_Ocultos]( @String VARCHAR(MAX) ) RETURNS VARCHAR(MAX) AS BEGIN DECLARE @Result VARCHAR(MAX) = '', @Contador INT = 1, @Total INT, @AdicionarBarra BIT = 0 SET @Total = LEN(@String) WHILE(@Contador <= @Total) BEGIN IF (PATINDEX('%[^ !"#$%&''()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ\^_`abcdefghijklmnopqrstuvwxyz|{}~€‚ƒ„…†‡ˆ‰Š‹ŒŽ‘’“”•–—˜™š›œžŸ¡¢£¤¥¦§¨©ª«¬®¯°±²³´µ¶·¸¹º»¼½¾¿ÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖ×ØÙÚÛÜÝÞßàáâãäåæçèéêëìíîïðñòóôõö÷øùúûüýþÿ[[]%', SUBSTRING(REPLACE(@String, ']', ''), @Contador, 1)) > 0) BEGIN SET @Result += (CASE WHEN @AdicionarBarra = 1 THEN ' | ' ELSE '' END) + 'Pos ' + CAST(@Contador AS VARCHAR(100)) + ': CHAR(' + CAST(ASCII(SUBSTRING(@String, @Contador, 1)) AS VARCHAR(5)) + ')' SET @AdicionarBarra = 1 END SET @Contador += 1 END RETURN @Result END GO |
Exemplo de utilização – Analisando uma string

Exemplo de utilização – Analisando registros de uma tabela
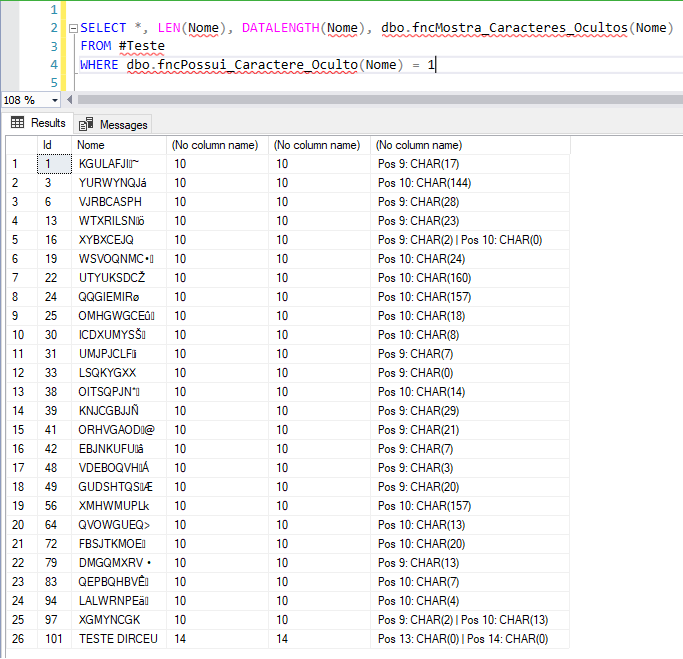
Retornando os dados sem os caracteres ocultos
Com a função fncMostra_Caracteres_Ocultos, consegui identificar quais os caracteres da minha string que estão fazendo o meu select de igualdade não retornar os dados. Vou testar se é isso mesmo:
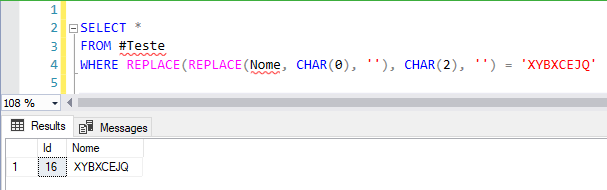
Caso você queira retornar as informações sem os caracteres “invisíveis” de uma forma ainda mais fácil, pode utilizar a função fncRemove_Caracteres_Ocultos:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
CREATE FUNCTION [dbo].[fncRemove_Caracteres_Ocultos]( @String VARCHAR(MAX) ) RETURNS VARCHAR(MAX) AS BEGIN DECLARE @Result VARCHAR(MAX), @StartingIndex INT = 0 WHILE (1 = 1) BEGIN SET @StartingIndex = PATINDEX('%[^ !"#$%&''()*+,-./0123456789:;<=>?@ABCDEFGHIJKLMNOPQRSTUVWXYZ\^_`abcdefghijklmnopqrstuvwxyz|{}~€‚ƒ„…†‡ˆ‰Š‹ŒŽ‘’“”•–—˜™š›œžŸ¡¢£¤¥¦§¨©ª«¬®¯°±²³´µ¶·¸¹º»¼½¾¿ÀÁÂÃÄÅÆÇÈÉÊËÌÍÎÏÐÑÒÓÔÕÖ×ØÙÚÛÜÝÞßàáâãäåæçèéêëìíîïðñòóôõö÷øùúûüýþÿ[[]%', REPLACE(@String, ']', '')) IF (@StartingIndex <> 0) SET @String = REPLACE(@String,SUBSTRING(@String, @StartingIndex,1),'') ELSE BREAK END SET @Result = REPLACE(@String,'|','') RETURN @Result END GO |
Exemplo de utilização da função fncRemove_Caracteres_Ocultos:

Observação importante: Assim como toda função UDF, essas funções podem causar uma lentidão ao serem utilizadas em grandes volumes de dados. Caso você precise utilizá-las com frequência em grandes volumes de dados, sugiro implementar funções utilizado SQLCLR, uma vez que geralmente elas entregam uma performance muito superior às funções UDF T-SQL, conforme eu já expliquei no artigo SQL Server – Comparação de performance entre Scalar Function e CLR Scalar Function.
Bom pessoal, espero que tenham gostado dessa dica que estou compartilhando com vocês e que essas funções podem ser úteis no dia a dia de vocês.
Um grande abraço e até o próximo artigo.
Você esta de parabéns pelo site, muita informação bacana e com certeza se minha empresa precisar vou recomenda-lo.Muito obrigado pela ajuda.
Na verdade com as duas aspas na frente do hífen parou de pegar todos os caracteres…
Boa tarde…
Ótimo artigo Dirceu, show de bola!
Tive o mesmo problema do Alexandre e consegui resolver adicionando duas aspas ” simples na frente do hífen. Com isso o “-” parou de ser sinalizado como carácter especial.
Acredito q isso tenha ocorrido pq o hífen faz parte da sintaxe do sql quando nos referimos a listas (ex [0-9]). É por isso Dirceu?
Porém gostaria agora de adicionar o tab a lista dos permitidos, e este eu não consegui ainda. Tem como eu colocar pelo código ASCII Dirceu?
Show de artigo e funções Dirceu, já estou utilizando. Obrigado.
Só fiquei com uma dúvida, no Patindex, há o caracter “-“, eu retirei das funções mas ele continua sendo retornado como o especial, pq será ?
Me manda sua função por email que vou ver o que você alterou e te falo o que faltou, beleza?