Fala pessoal!
Neste post mega esperado, vou comentar sobre as novidades que podemos esperar do SQL Server 2019, que há muito tempo deixou de ser um SGBD (Sistema Gerenciador de Banco de Dados) para se transformar em uma verdadeira plataforma de dados da Microsoft, unindo banco de dados, BI, Machine Learning e Big Data/Analytics.
Gostaria de ver novidades sobre as versões anteriores ?
O vídeo institucional no começo desse post já tem alguns destaques do SQL Server 2019 (as quais vou comentar logo abaixo) e que nos mostra como a Microsoft está de olho no mercado de Big Data e também, trazendo melhorias significativas para a sua plataforma de dados.
Transcrição do Vídeo – SQL Server 2019 + Polybase + Spark + Big Data + HDFS
Visualizar conteúdo
O crescente volume de dados cria grandes mares de oportunidades para aqueles que podem navegar nele. O SQL Server 2019 ajuda você a ficar à frente da mudança de horários, tornando a integração, o gerenciamento e a inteligência dos dados mais fáceis e intuitivos do que nunca.
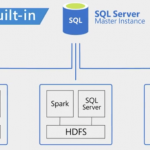
Com o SQL Server 2019, você pode criar uma única camada de dados virtual acessível a quase todos os aplicativos. A virtualização de dados do Polybase lida com a complexidade de integrar todas as suas origens e formatos de dados sem exigir que você os replique ou mova. Você pode simplificar o gerenciamento de dados usando os Big Data Clusters do SQL Server 2019 implantados no Kubernetes. Cada nó de um Big Data Cluster inclui o mecanismo relacional do SQL Server, o armazenamento HDFS e o Spark, que permitem armazenar e gerenciar seus dados usando as ferramentas de sua escolha.
O SQL Server 2019 facilita a criação de aplicativos inteligentes com big data. Agora você pode executar tarefas do Spark para analisar dados estruturados e não estruturados, treinar modelos sobre dados de qualquer lugar com o SQL Server Machine Learning Services ou Spark ML e consultar dados de qualquer lugar usando uma rica experiência de notebook incorporada no Azure Data Studio. A corrente de dados não está diminuindo, mas não precisa afundar seus negócios. Navegue com o SQL Server 2019 e encurte a distância entre dados e ação.
Big Data + Analytics
Visualizar conteúdo
O SQL Server continua a adotar o código aberto, desde o suporte do SQL Server 2017 para Linux e contêineres ao SQL Server 2019, agora abrangendo o Spark e o HDFS para oferecer uma plataforma de dados unificada. Com o SQL Server 2019, todos os componentes necessários para realizar análises sobre seus dados são incorporados em um cluster gerenciado, que é fácil de implantar e pode ser dimensionado de acordo com as necessidades do seu negócio. HDFS, Spark, Knox, Ranger, Livy, todos vêm empacotados junto com o SQL Server e são rapidamente e facilmente implantados como containers Linux no Kubernetes. O SQL Server simplifica o gerenciamento de todos os seus dados corporativos removendo quaisquer barreiras que existam atualmente entre dados estruturados e não estruturados.
Veja como podemos facilitar a eliminação de barreiras para a percepção de todos os seus dados, fornecendo uma visualização dos seus dados em toda a organização:
Simplifique a análise de big data para usuários do SQL Server. O SQL Server 2019 facilita o gerenciamento de ambientes de big data. Ele vem com tudo o que você precisa para criar um data lake, incluindo HDFS e Spark fornecidos pela Microsoft e ferramentas de análise, todos profundamente integrados ao SQL Server e totalmente suportados pela Microsoft. Agora, você pode executar aplicativos, análises e IA sobre dados estruturados e não estruturados – usando consultas T-SQL familiares ou pessoas familiarizadas com o Spark podem usar Python, R, Scala ou Java para executar tarefas do Spark para preparação ou análise de dados. o mesmo cluster integrado.
Ofereça aos desenvolvedores, analistas de dados e engenheiros de dados uma única fonte para todos os seus dados – estruturados e não estruturados – usando suas ferramentas favoritas. Com o SQL Server 2019, os cientistas de dados podem analisar facilmente os dados no SQL Server e no HDFS por meio dos trabalhos do Spark. Os analistas podem executar análises avançadas sobre big data usando o SQL Server Machine Learning Services: treinar grandes conjuntos de dados no Hadoop e operacionalizar no SQL Server. Os cientistas de dados podem usar uma nova experiência de notebook em execução no mecanismo de notebooks Jupyter em uma nova extensão do Azure Data Studio para realizar interativamente análises avançadas de dados e compartilhar facilmente a análise com seus colegas.
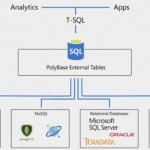
Divida os silos de dados e forneça uma visualização em todos os seus dados usando a virtualização de dados. A partir do SQL Server 2016, o PolyBase permitiu que você executasse uma consulta T-SQL dentro do SQL Server para extrair dados de seu Data Lake e retorná-los em um formato estruturado – tudo sem mover ou copiar os dados. Agora, no SQL Server 2019, estamos expandindo esse conceito de virtualização de dados para fontes de dados adicionais, incluindo Oracle, Teradata, MongoDB, PostgreSQL e outras. Usando o novo PolyBase, você pode dividir silos de dados e combinar facilmente dados de várias fontes usando a virtualização para evitar o tempo, esforço, riscos de segurança e dados duplicados criados pela movimentação e replicação de dados. Novos “pools de dados” e “pools de dados” elasticamente escalonáveis tornam a consulta de dados virtualizados mais rápida, armazenando dados em cache e distribuindo a execução de consultas em muitas instâncias do SQL Server.
Melhorias de Performance
Visualizar conteúdo
Desempenho líder do setor – o banco de dados inteligente
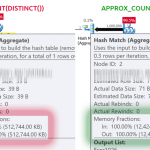
A família de recursos do Intelligent Query Processing se baseia em recursos de ajuste de desempenho do Adaptive Query Processing do SQL Server 2017, incluindo feedback de concessão de memória no modo Row, COUNT DISTINCT aproximado, modo Batch no rowstore
O suporte a memória persistente foi aprimorado nesta versão com um novo caminho otimizado de I/O, disponível para interação com o armazenamento de memória persistente.
A infra-estrutura do Lightweight query profiling agora está habilitada por padrão para fornecer estatísticas do operador por consulta a qualquer momento e em qualquer lugar que você precisar.
Mudanças na estimativa de linhas ao utilizar tabelas variáveis (compilação adiada de variável de tabela). Até o SQL Server 2019, o otimizador de consulta SEMPRE estimava 1 linha retornada ao utilizar variáveis do tipo tabela, gerando muitas vezes, operadores incorretos quando utilizados grandes massas de dados nesse tipo de objeto e tendo uma performance muito ruim. Isso fazia com que muitas pessoas utilizassem tabelas temporárias ou o hint OPTION (RECOMPILE) para evitar esse tipo de comportamento. Na versão 2019, o otimizador de consulta irá tentar estimar um número mais próximo do real, fazendo com que os resultados utilizando variáveis do tipo tabela sejam geralmente melhores que os resultados em versões anteriores. Para saber mais sobre essa novidade, veja este post do Brent Ozar
Row mode memory grant feedback. O SQL Server 2017 introduziu o Row mode memory grant feedback, que é descrito em detalhes aqui. Essencialmente, para qualquer concessão de memória envolvida com um plano que envolva operadores de modo em lote, o SQL Server avaliará a memória usada pela consulta e a comparará à memória solicitada. Se a memória solicitada for muito baixa ou muito alta, levando a spills ou desperdício de memória, ela ajustará a concessão de memória associada ao plano de execução na próxima vez que for executada. Isso reduzirá a concessão para permitir uma concorrência maior ou aumentá-la para melhorar o desempenho.
Agora, também obtemos esse comportamento para as consultas no modo de linha, sob o nível de compatibilidade 150. Se uma consulta for encontrada em um disco, a concessão de memória será aumentada para execuções subseqüentes. Se a memória real usada pela consulta for menor que a metade da memória concedida, as solicitações de concessão subseqüentes serão menores. Brent Ozar entra em mais detalhes em seu post sobre Adaptive Memory Grants.
Modo em lote sobre rowstore – Desde o SQL Server 2012, as consultas em tabelas com índices columnstore se beneficiaram dos aprimoramentos de desempenho do modo em lote. As melhorias acontecem devido ao processador de consultas executar processamento em lote em vez de linha por linha. As linhas também surgem do mecanismo de armazenamento em lotes e os operadores de troca de paralelismo podem ser evitados.
Sob o nível de compatibilidade 150, o SQL Server 2019 escolherá automaticamente o modo de lote em certos casos, mesmo quando não houver um índice de columnstore, que muitas vezes não pode ser criado por vários restrições técnicas e/ou conceituais, como por exemplo, falta de suporte à triggers
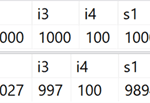
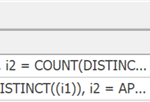
Nova função de agregação APPROX_COUNT_DISTINCT – Essa nova função de agregação é projetada para cenários de data warehouse e é equivalente a COUNT (DISTINCT ()). Em vez de executar operações de classificação distintas dispendiosas para determinar as contagens reais, ela se baseia em estatísticas para obter algo relativamente preciso. Você deve descobrir que a margem de erro está dentro de 2% da contagem precisa em 97% do tempo, o que geralmente é suficiente para análises de alto nível e a economia de memória utilizada é bem considerável.
Resultados dos testes:
Query-scoped compatibility level hints – Tem uma consulta específica que funciona melhor em um determinado nível de compatibilidade que não é o mesmo que o banco de dados atual? Agora você pode fazer isso com os novos query hints, suportando seis diferentes níveis de compatibilidade e cinco diferentes modelos de estimativa de cardinalidade. A seguir, os níveis de compatibilidade disponíveis, a sintaxe de exemplo e o modelo CE usado em cada caso. Você pode ver como isso pode afetar as estimativas, mesmo para as visualizações do catálogo do sistema:
Para visualizar todos os hints disponíveis, você pode consultar a DMV sys.dm_exec_valid_use_hints.
Estimativas de compressão de índices columnstore – Nas versões atuais, o procedimento sys.sp_estimate_data_compression_savings tem uma verificação para o tipo de compressão (NONE, ROW e PAGE). No SQL Server 2019, essa verificação foi alterada para permitir o cálculo de estimativa dos índices columnstore.
Isso é uma ótima notícia, pois permite prever o impacto da adição de um índice columnstore a uma tabela que não possui nenhum, ou converter uma tabela ou partição no formato columnstore mais agressivo, sem precisar restaurar a tabela para outro sistema e realmente aplicar na prática para fazer essa análise.
Nova função para recuperar informações da página – DBCC PAGE e DBCC IND foram usados por um longo tempo para reunir informações sobre as páginas que compõem uma partição, índice ou tabela. Mas eles são comandos não documentados e não suportados e podem ser muito tediosos para automatizar soluções em torno de problemas que envolvem mais de um índice ou página.
Junto veio sys.dm_db_database_page_allocations, uma função de gerenciamento dinâmico que retorna um conjunto representando todas as páginas no objeto especificado. Ainda não documentada, essa função exibe um problema de pushdown de predicado que pode ser um problema real em tabelas maiores: mesmo para obter as informações sobre uma única página, ele precisa ler toda a estrutura, o que pode ser bastante proibitivo.
O SQL Server 2019 introduz outro DMF, sys.dm_db_page_info. Isso retorna basicamente todas as informações em uma página, sem a sobrecarga das alocações DMF. Em versões atuais, no entanto, você já deve saber o número da página que está procurando para usar a função. Isso pode ser intencional, pois pode ser a única maneira de garantir o desempenho. Portanto, se você estiver tentando determinar todas as páginas em um índice ou tabela, ainda precisará usar as alocações DMF.
Segurança Avançada – Computação Confidencial
Visualizar conteúdo
Always Encrypted com enclaves seguros estende a tecnologia de criptografia do lado do cliente introduzida no SQL Server 2016. Os enclaves seguros protegem dados confidenciais em um enclave criado por hardware ou software dentro do banco de dados, protegendo-o contra malware e usuários privilegiados, permitindo operações avançadas em dados criptografados. Hoje, o Always Encrypted protege os dados confidenciais criptografando / descriptografando em cada extremidade do processo. Infelizmente, isso introduz restrições de processamento muitas vezes críticas, como não ser capaz de realizar cálculos e filtragem – o que significa que todo o conjunto de dados deve ser enviado para executar, digamos, uma pesquisa de intervalo.
Um enclave é uma área protegida de memória na qual esses cálculos e filtragem podem ser delegados (no Windows, isso usa segurança baseada em virtualização) – os dados permanecem criptografados na engine, mas podem ser criptografados ou descriptografados, com segurança, dentro do enclave. Basta adicionar a opção ENCLAVE_COMPUTATIONS à chave mestra, o que você pode fazer no SSMS marcando a caixa de seleção “Allow enclave computations” ao criar a Master Key de uma coluna
o recurso SQL Data Discovery and Classification agora está incorporado ao mecanismo do SQL Server com novos metadados e suporte de auditoria para ajudar no GDPR e em outras necessidades de conformidade. No SSMS 17.5, a equipe do SQL Server adicionou a capacidade de classificar dados no SSMS, para que você pudesse identificar colunas que pudessem conter informações confidenciais ou interferir na conformidade com vários padrões (HIPAA, SOX, PCI e, é claro, GDPR) . O assistente usa um algoritmo para sugerir colunas que provavelmente causarão problemas de conformidade, mas você pode adicionar suas próprias, ajustar suas sugestões e eliminar quaisquer colunas da lista. Ele armazena essas classiciations usando propriedades estendidas; um relatório baseado em SSMS usa essa mesma informação para exibir as colunas que foram identificadas. Fora do relatório, essas propriedades não são altamente visíveis.
No SQL Server 2019, há um novo comando para esses metadados, já disponível no Banco de Dados SQL do Azure, chamado ADD SENSITIVITY CLASSIFICATION. Isso permite que você faça o mesmo tipo de assistente do SSMS, mas as informações não são mais armazenadas como extended property, e qualquer acesso a esses dados é exibido automaticamente em auditorias em uma nova coluna XML chamada data_sensitivity_information. Contém todos os tipos de informações que foram acessadas durante o evento auditado.
Agora, o gerenciamento de certificados agora está mais fácil usando o SQL Server Configuration Manager. O gerenciamento de certificados SSL e TLS sempre foi trabalhoso, e muitas pessoas precisam executar muitos trabalhos tediosos e scripts internos para implantar e manter certificados em toda a empresa. Com o SQL Server 2019, as atualizações do SQL Server Configuration Manager ajudarão você a visualizar e validar rapidamente os certificados de qualquer instância, localizar certs próximos à expiração e sincronizar implantações de certificados em todas as réplicas em um Availability Group (primário) ou todos os nós em um Failover Cluster Instance (nó ativo).
Disponibilidade de missão crítica – alto tempo de uptime
Visualizar conteúdo
Always On Availability Groups foram aprimorados para incluir o redirecionamento automático de conexões para o primário, com base na intenção de leitura / gravação. Esse recurso permite configurar redirecionamentos sem um listener, para que você possa alternar uma conexão para o primário, mesmo que um secundário seja explicitamente nomeado na cadeia de conexão. Você pode usar esse recurso quando a tecnologia de cluster não oferece suporte a um listener, ou quando você está usando AGs sem cluster, ou quando você tem um esquema de redirecionamento complexo em um cenário de várias sub-redes. Isso impedirá que uma conexão, por exemplo, tente gravar operações em uma réplica somente leitura (e falhe).
configurações de alta disponibilidade para o SQL Server rodando em contêineres podem ser ativadas com Always On Availability Groups usando o Kubernetes.
Resumable online indexes foram melhorados no SQL Server 2019 e agora podem ser utilizados na criação do índice (que será criado de forma ONLINE e RESUMABLE) e também em índices do tipo COLUMNSTORE. Além disso, as configurações de escopo do database (Database scoped configutation) podem ser alteradas para que os índices sejam criados desta forma por padrão.
Os aprimoramentos no SQL Graph incluem suporte de correspondência com o T-SQL MERGE e restrições de borda.
O novo suporte a UTF-8 oferece aos clientes a capacidade de reduzir o espaço de armazenamento do SQL Server para dados utilizando UTF-8. O SQL Server 2012 adicionou suporte para UTF-16 e caracteres complementares por meio de um conjunto de collations com um sufixo _SC, como Latin1_General_100_CI_AI_SC, para uso com colunas Unicode (nchar / nvarchar). No SQL Server 2017, é possível importar e exportar dados no formato UTF-8 para e a partir dessas colunas, por meio de instalações como BCP e BULK INSERT.
No SQL Server 2019, há novas collations para oferecer suporte nativo ao armazenamento de dados UTF-8 no SQL Server. Assim, você pode criar uma coluna char ou varchar para armazenar adequadamente dados UTF-8 usando novos agrupamentos com um sufixo _SC_UTF8, como Latin1_General_100_CI_AI_SC_UTF8. Isso pode ajudar a melhorar a compatibilidade com aplicativos externos e outras plataformas e sistemas de banco de dados, sem pagar as penalidades de desempenho e armazenamento do nvarchar.
A nova extensão de linguagem Java permitirá que você chame um programa Java pré-compilado e execute de modo seguro, o código Java no mesmo servidor com o SQL Server. Isso reduz a necessidade de mover dados e melhora o desempenho do aplicativo, aproximando suas cargas de trabalho de seus dados.
O Machine Learning Services tem vários aprimoramentos, incluindo suporte a Windows Failover cluster, modelos particionados e suporte para SQL Server no Linux.
Melhorias no Multiplataforma
Visualizar conteúdo
Recursos adicionais para o SQL Server no Linux incluem transações distribuídas, replicação, Polybase, Machine Learning Services, notificações de memória e suporte a OpenLDAP.
Os contêineres têm novos aprimoramentos, incluindo o uso do novo Microsoft Container Registry, com suporte para imagens RedHat Enterprise Linux e Always On Availability Groups para Kubernetes.
Suporte ao SQL Server 2019 no Azure Data Studio
Visualizar conteúdo
O suporte expandido para mais cargas de trabalho de dados no SQL Server requer ferramentas expandidas. Como a Microsoft trabalhou com usuários de sua plataforma de dados, vimos a união de personas anteriormente díspares: administradores de banco de dados, cientistas de dados, desenvolvedores de dados, analistas de dados e novas funções ainda em definição.
Cada vez mais, esses usuários desejam usar as mesmas ferramentas para trabalhar juntos, sem interrupções, no local e na nuvem, usando dados relacionais e não estruturados, trabalhando com cargas de trabalho OLTP, ETL, analíticas e de fluxo contínuo.
O Azure Data Studio (antigo SQL Operations Studio) oferece uma experiência de editor moderna com IntelliSense ultrarrápido, code snippets, integração de código-fonte e um terminal integrado. Ele é projetado tendo em mente, um usuário da plataforma de dados, permitindo gerar gráficos e insights a partir das consultas realizadas, um bloco de anotações integrado e painéis personalizáveis. Desta forma, a Microsoft vem focando neste perfil no Azure Data Studio, e mantendo o SQL Server Management Studio voltado para o perfil de Administradores de Banco de Dados (DBAs)
O Azure Data Studio atualmente oferece suporte interno para o SQL Server local (On-premise) e também na nuvem (Azure SQL Database), além do suporte (ainda beta) para Azure Managed Instance e o Azure SQL Data Warehouse.
O Azure Data Studio está apresentando hoje, uma nova extensão preview para adicionar suporte a alguns recursos do SQL Server 2019. A extensão oferece conectividade e ferramentas para clusters de big data do SQL Server, incluindo uma prévia da primeira experiência ao recurso de anotações no conjunto de ferramentas do SQL Server e o novo assistente “PolyBase Create External Table”, que facilita o acesso a dados de instâncias remotas do SQL Server e do Oracle.
Conforme apontado pelo Brent Ozar nesse post aqui, o SQL Server 2019 nos traz uma série de mudanças nas mensagens de erro e alertas tradicionais (além de novas mensagens de erro, para os novos recursos).
Entre a extensa lista que mudanças e novidades nas mensagens, destaco algumas delas:
3911 – Persistent version store is full. New version(s) could not be added. A transaction that needs to access the version store may be rolled back. Please refer to BOL on how to increase database max size.
10661 – The refresh operation for all snapshot views failed because there was another refresh operation (either for all or a single snapshot view) in progress.
9113 – Warning: Creating and updating statistics will force FULL SCAN in this version of SQL Server. If persisting sample percent, persisted_sample_percent will be 100.
12112 – Warning: %ls statement is being forced to run WITH (%S_MSG = ON) because the ELEVATE_%S_MSG database scoped configuration is set to FAIL_UNSUPPORTED. The statement may fail. See the SQL Server error log for more information.
5871 – Cannot set the column encryption enclave type to Virtual Secure Mode (VSM) – the operating system does not support VSM.
2628 – String or binary data would be truncated in table ‘%.*ls’, column ‘%.*ls’. Truncated value: ‘%.*ls’.
Sim, você viu isso certo! Quem nunca perdeu preciosos minutos tentando identificar qual coluna e qual valor que estourou o limite de um campo varchar ? No SQL Server 2019 isso não deve acontecer mais (Obs: Fiz um teste e ainda acontece.. vamos aguardar a versão final).
Novos objetos de sistema e DMV’s
Visualizar conteúdo
Como era de esperar, com novos recursos e aprimoramentos, novos objetos de sistema, como Stored Procedures e DMV’s são criados/alterados para suportar essas mudanças no produto. Com isso, o Brent Ozar escreveu este artigo aqui com um resumo dessas alterações realizadas em objetos de sistema, as quais eu destaco os novos objetos criados:
Novas Stored Procedures
sys.sp_add_feature_restriction
sys.sp_autoindex_cancel_dta
sys.sp_autoindex_invoke_dta
sys.sp_cloud_update_blob_tier
sys.sp_configure_automatic_tuning
sys.sp_diagnostic_showplan_log_dbid
sys.sp_drop_feature_restriction
sys.sp_execute_remote
sys.sp_force_slog_truncation
sys.sp_internal_alter_nt_job_limits
sys.sp_rbpex_exec_cmd
sys.sp_set_distributed_query_context
sys.sp_set_session_resource_group
sys.sp_showinitialmemo_xml
sys.sp_xa_commit
sys.sp_xa_end
sys.sp_xa_forget
sys.sp_xa_forget_ex
sys.sp_xa_init
sys.sp_xa_init_ex
sys.sp_xa_prepare
sys.sp_xa_prepare_ex
sys.sp_xa_recover
sys.sp_xa_rollback
sys.sp_xa_rollback_ex
sys.sp_xa_start
sys.xp_copy_file
sys.xp_copy_files
sys.xp_delete_files
sys.sp_change_repl_serverport
sys.sp_getdistributorplatform
sys.sp_MSget_server_portinfo
sys.sp_MSset_repl_serveroptions
sys.sp_persistent_version_cleanup
sys.sp_persistent_version_store
sys.sp_sqljdbc_xa_install
sys.sp_sqljdbc_xa_uninstall
Novas tabelas/views
sys.dm_column_encryption_enclave
sys.dm_column_encryption_enclave_operation_stats
sys.dm_db_missing_index_group_stats_query
sys.dm_distributed_exchange_stats
sys.dm_hadr_ag_threads
sys.dm_hadr_db_threads
sys.dm_os_job_object
sys.dm_tran_aborted_transactions
sys.edge_constraint_clauses
sys.edge_constraints
sys.external_libraries_installed
sys.sensitivity_classifications
sys._trusted_assemblies
sys.persistent_version_store
sys.persistent_version_store_long_term
sys.tbl_server_resource_stats
Novas funções
sys.dm_db_page_info
sys.fn_dbslog
sys.fn_getproviderstring
Segue um outro vídeo com um resumo dos recursos apresentados:





Sensacional!
Parabens pelo post Mestre Dirceu, abrs.
Foi de longe o melhor post que vi esse mês.
Parabéns Dirceu…..
Irado demais, ótimas informações Dirceu.