
- SQL Server – Introdução ao estudo de Performance Tuning
- Entendendo o funcionamento dos índices no SQL Server
- SQL Server – Como identificar uma query lenta ou “pesada” no seu banco de dados
- SQL Server – Dicas de Performance Tuning: Conversão implícita? NUNCA MAIS!
- SQL Server – Comparação de performance entre Scalar Function e CLR Scalar Function
- SQL Server – Dicas de Performance Tuning: Qual a diferença entre Seek Predicate e Predicate?
- SQL Server – Utilizando colunas calculadas (ou colunas computadas) para Performance Tuning
- SQL Server – Como identificar e coletar informações de consultas demoradas utilizando Extended Events (XE)
- SQL Server – Como identificar todos os índices ausentes (Missing indexes) de um banco de dados
- SQL Server e Azure SQL Database: Como Identificar ocorrências de Key Lookup através da plancache
Fala pessoal!
Nesse artigo eu gostaria de compartilhar com vocês um script do Kendal Van Dyke para identificar/encontrar ocorrências de Key Lookup através da plancache, o que pode ser muito útil para facilmente identificar possíveis bons candidatos para uma análise de performance.
Como vocês sabem, ocorrências de KeyLookup geralmente causam um impacto no desempenho bem grande e podem ser facilmente corrigidos criando/alterando índices.
O que é e como evitar o Key Lookup e o RID Lookup
Conforme eu já havia explicado no artigo Entendendo o funcionamento dos índices no SQL Server, quando é realizada uma consulta em uma tabela, o otimizador de consultas do SQL Server irá determinar qual o melhor método de acesso ao dados de acordo com as estatísticas coletadas e escolher o que tiver o menor custo.
Como o índice clustered é a própria tabela, gerando um grande volume de dados, é geralmente utilizado o índice não clustered de menor custo para a consulta.
Isso pode gerar um problema, pois, muitas vezes, o índice não clustered será utilizado para a busca das informações indexadas (Index Seek NonClustered), mas nem todas as colunas solicitadas no select fazem parte do índice.
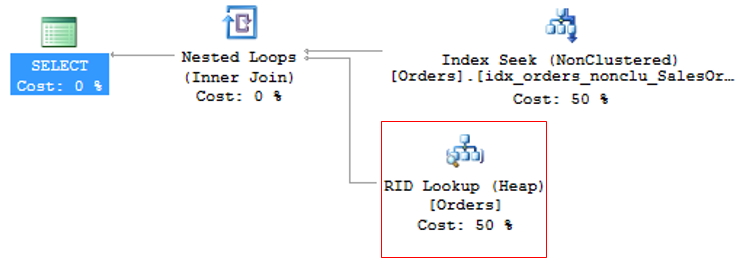
Quando isso acontece, o índice clustered também terá que ser utilizado para retornar as informações restantes, utilizando o ponteiro para a posição exata da informação no índice clustered (ou o ROWID, caso a tabela não tenha índice cluster).
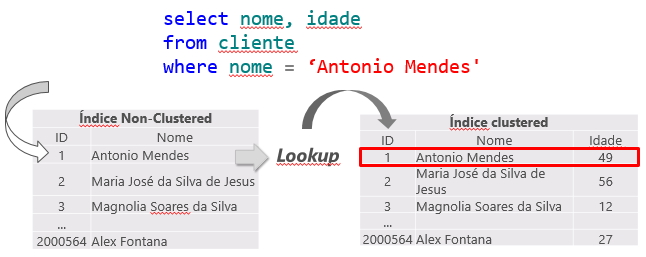
Essa operação é chamada de Key Lookup, no caso de tabelas com índice clustered ou RID Lookup (RID = Row ID) para tabelas que não possuem índice clustered (chamadas tabelas HEAP) e por gerar 2 operações de leituras para uma única consulta, deve ser evitada sempre que possível.
Key Lookup
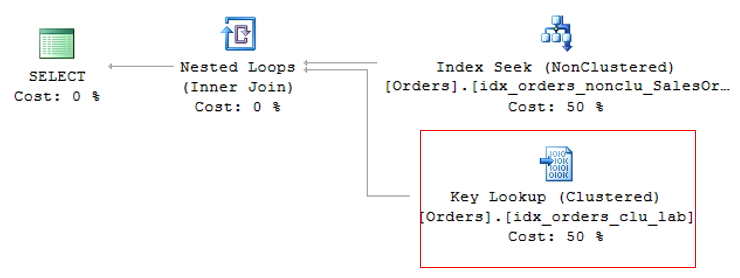
RID Lookup
Para evitar o KeyLookup basta utilizar a técnica de cobrir o índice (Covering index), que consiste em adicionar ao índice NonClustered (INCLUDE) as principais colunas que são utilizadas nas consultas à tabela. Isso faz com que o otimizador de consulta consiga obter todas as informações lendo apenas o índice escolhido, sem precisar ler também o índice clustered.
Entretanto, deve-se tomar muita atenção na modelagem dos índices. Não é recomendável adicionar todas as colunas da tabela no índice não cluster, uma vez que ele ficará tão grande que ele não será mais efetivo e o otimizador de consulta poderá até mesmo decidir em não utilizá-lo e preferir o operador Index Scan, que faz a leitura sequencial de todo o índice, prejudicando a performance das consultas.
Para evitar o RID Lookup, basta criar o índice clustered na tabela e prestar atenção aos eventos de Key Lookup que possam vir a surgir.
Como Identificar/Encontrar ocorrências de Key Lookup através da plancache
Agora que você entendeu o que é um Key Lookup e como corrigir, vamos agora aprender como identificar esses eventos de forma fácil e rápida.
Método 1: Utilizando um simples LIKE
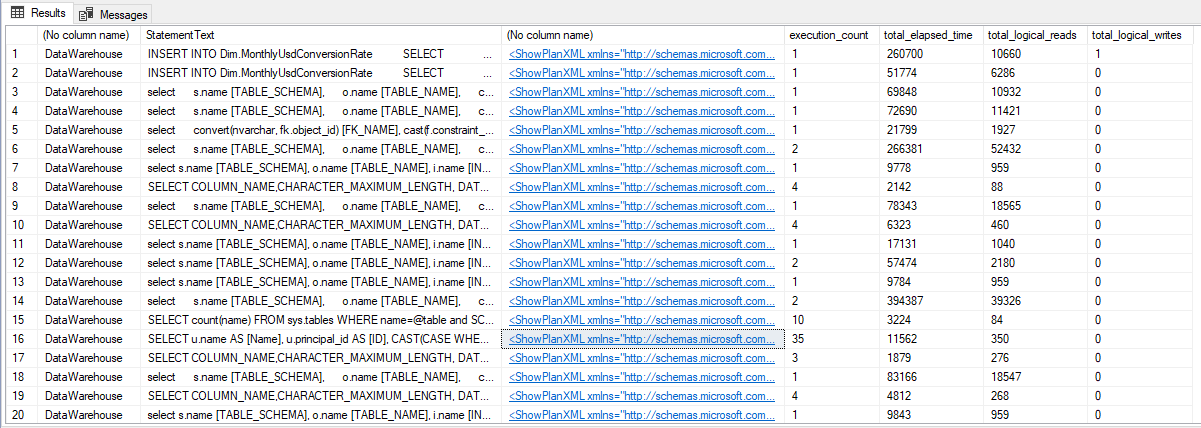
Essa consulta abaixo é relativamente simples, fazendo apenas uma consulta em algumas DMV’s e uma consulta textual usando LIKE no plano de execução para procurar pela expressão Lookup=”1″ dentro do XML. O resultado costuma ser bem preciso, mas falso positivos podem aparecer.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
SELECT DB_NAME([detqp].[dbid]), SUBSTRING([dest].[text], ( [deqs].[statement_start_offset] / 2 ) + 1, ( CASE [deqs].[statement_end_offset] WHEN -1 THEN DATALENGTH([dest].[text])ELSE [deqs].[statement_end_offset] END - [deqs].[statement_start_offset] ) / 2 + 1) AS [StatementText], CAST([detqp].[query_plan] AS XML), [deqs].[execution_count], [deqs].[total_elapsed_time], [deqs].[total_logical_reads], [deqs].[total_logical_writes] FROM [sys].[dm_exec_query_stats] AS [deqs] CROSS APPLY [sys].dm_exec_text_query_plan([deqs].[plan_handle], [deqs].[statement_start_offset], [deqs].[statement_end_offset]) AS [detqp] CROSS APPLY [sys].dm_exec_sql_text([deqs].[sql_handle]) AS [dest] WHERE [detqp].[query_plan] LIKE '%Lookup="1"%'; |
Resultado:
Método 2: Utilizando XPath no XML do plano de execução
Esse segundo método é bem mais completo, retornando mais informações e utilizando fórmulas XPath para navegar dentro do XML do plano de execução e retornar os dados de forma mais precisa e correta.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 |
/********************************************************************************************* Find Key Lookups in Cached Plans v1.00 (2010-07-27) (C) 2010, Kendal Van Dyke Feedback: mailto:[email protected] License: This query is free to download and use for personal, educational, and internal corporate purposes, provided that this header is preserved. Redistribution or sale of this query, in whole or in part, is prohibited without the author's express written consent. Note: Exercise caution when running this in production! The function sys.dm_exec_query_plan() is resource intensive and can put strain on a server when used to retrieve all cached query plans. Consider using TOP in the initial select statement (insert into @plans) to limit the impact of running this query or run during non-peak hours *********************************************************************************************/ DECLARE @plans TABLE ( [query_text] NVARCHAR(MAX), [o_name] sysname, [execution_plan] XML, [last_execution_time] DATETIME, [execution_count] BIGINT, [total_worker_time] BIGINT, [total_physical_reads] BIGINT, [total_logical_reads] BIGINT ); DECLARE @lookups TABLE ( [table_name] sysname, [index_name] sysname, [index_cols] NVARCHAR(MAX) ); WITH [query_stats] AS ( SELECT [sql_handle], [plan_handle], MAX([last_execution_time]) AS [last_execution_time], SUM([execution_count]) AS [execution_count], SUM([total_worker_time]) AS [total_worker_time], SUM([total_physical_reads]) AS [total_physical_reads], SUM([total_logical_reads]) AS [total_logical_reads] FROM [sys].[dm_exec_query_stats] GROUP BY [sql_handle], [plan_handle] ) INSERT INTO @plans ( [query_text], [o_name], [execution_plan], [last_execution_time], [execution_count], [total_worker_time], [total_physical_reads], [total_logical_reads] ) SELECT /*TOP 50*/ [sql_text].[text], CASE WHEN [sql_text].[objectid] IS NOT NULL THEN ISNULL(OBJECT_NAME([sql_text].[objectid], [sql_text].[dbid]), 'Unresolved') ELSE CAST('Ad-hoc\Prepared' AS sysname) END, [query_plan].[query_plan], [query_stats].[last_execution_time], [query_stats].[execution_count], [query_stats].[total_worker_time], [query_stats].[total_physical_reads], [query_stats].[total_logical_reads] FROM [query_stats] CROSS APPLY [sys].dm_exec_sql_text([query_stats].[sql_handle]) AS [sql_text] CROSS APPLY [sys].dm_exec_query_plan([query_stats].[plan_handle]) AS [query_plan] WHERE [query_plan].[query_plan] IS NOT NULL; ;WITH XMLNAMESPACES ( DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan' ), [lookups] AS ( SELECT DB_ID(REPLACE(REPLACE([keylookups].[keylookup].[value]('(Object/@Database)[1]', 'sysname'), '[', ''), ']', '')) AS [database_id], OBJECT_ID([keylookups].[keylookup].[value]('(Object/@Database)[1]', 'sysname') + '.' + [keylookups].[keylookup].[value]('(Object/@Schema)[1]', 'sysname') + '.' + [keylookups].[keylookup].[value]('(Object/@Table)[1]', 'sysname')) AS [object_id], [keylookups].[keylookup].[value]('(Object/@Database)[1]', 'sysname') AS [database], [keylookups].[keylookup].[value]('(Object/@Schema)[1]', 'sysname') AS [schema], [keylookups].[keylookup].[value]('(Object/@Table)[1]', 'sysname') AS [table], [keylookups].[keylookup].[value]('(Object/@Index)[1]', 'sysname') AS [index], REPLACE([keylookups].[keylookup].[query]('for $column in DefinedValues/DefinedValue/ColumnReference return string($column/@Column)').[value]('.', 'varchar(max)'), ' ', ', ') AS [columns], [plans].[query_text], [plans].[o_name], [plans].[execution_plan], [plans].[last_execution_time], [plans].[execution_count], [plans].[total_worker_time], [plans].[total_physical_reads], [plans].[total_logical_reads] FROM @plans AS [plans] CROSS APPLY [execution_plan].nodes('//RelOp/IndexScan[@Lookup="1"]') AS [keylookups]([keylookup]) ) SELECT [lookups].[database], [lookups].[schema], [lookups].[table], [lookups].[index], [lookups].[columns], [index_stats].[user_lookups], [index_stats].[last_user_lookup], [lookups].[execution_count], [lookups].[total_worker_time], [lookups].[total_physical_reads], [lookups].[total_logical_reads], [lookups].[last_execution_time], [lookups].[o_name] AS [object_name], [lookups].[query_text], [lookups].[execution_plan] FROM [lookups] JOIN [sys].[dm_db_index_usage_stats] AS [index_stats] ON [lookups].[database_id] = [index_stats].[database_id] AND [lookups].[object_id] = [index_stats].[object_id] WHERE [index_stats].[user_lookups] > 0 AND [lookups].[database] NOT IN ( '[master]', '[model]', '[msdb]', '[tempdb]' ) ORDER BY [index_stats].[user_lookups] DESC, [lookups].[total_physical_reads] DESC, [lookups].[total_logical_reads] DESC; |
Resultado:

Utilizando uma das consultas acima, você irá facilmente identificar as consultas que estão apresentando o operador de Key Lookup. Agora que você já sabe o que é e como resolver, já pode analisar se vale a pena criar um índice para cobrir essa consulta ou não (Aumento de Espaço em Disco + Aumento no Tempo de Escrita vs Melhoria da Leitura).
Não se esqueça de analisar também os Índices ausentes do seu ambiente. Para saber mais sobre isso, leia o artigo SQL Server – Como identificar todos os índices ausentes (Missing indexes) de um banco de dados.
Um grande abraço e até a próxima!