
- O que mudou no SQL Server 2008 em relação ao T-SQL – Na visão dos Desenvolvedores
- O que mudou no SQL Server 2012 em relação ao T-SQL – Na visão dos Desenvolvedores
Fala pessoal!
Tudo certo ?
No post de hoje, vou compartilhar com vocês uma pesquisa que venho fazendo já há algum tempo, sobre os novos recursos do SQL Server a cada versão, com o foco nos desenvolvedores de query e rotinas de banco de dados. Nos ambientes que trabalho, vejo que muitos acabam “reinventando a roda” ou criando funções UDF para realizar determinadas tarefas (as quais sabemos que são péssimos para performance) quando o próprio SQL Server já provê soluções nativas para isso.
Meu objetivo nesse post é ajudar a você, que está utilizando versões antigas do SQL Server, a avaliar quais as vantagens e novos recursos (apenas na visão do desenvolvedor) que você terá acesso ao atualizar seu SQL Server.
SQL Server – O que mudou no T-SQL na versão 2012 ?
Paginação de dados com OFFSET e FETCH
Visualizar conteúdoCom o surgimento do ROW_NUMBER() no SQL Server 2005, muitas pessoas passaram a utilizar essa função para criar paginação de dados, funcionando desta forma:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
DECLARE @Pagina INT = 5, @ItensPorPagina INT = 10 SELECT * FROM ( SELECT [name], ROW_NUMBER() OVER(ORDER BY [name]) AS Ranking FROM sys.objects ) A WHERE A.Ranking >= ((@Pagina - 1) * @ItensPorPagina) + 1 AND A.Ranking < (@Pagina * @ItensPorPagina) + 1 |
Resultado:

Entretanto, a partir do SQL Server 2012 temos a funcionalidade de paginação nativa no próprio SQL Server e que muita gente acaba não utilizando por desconhecimento. Estamos falando do recurso OFFSET e FETCH, que funcionam juntos para permitir que possamos paginar os nossos resultados antes de exibir e enviá-los para as aplicações e clientes.
Vejam com o seu uso é simples:
|
1 2 3 4 5 |
SELECT [name] FROM sys.objects ORDER BY [name] OFFSET 40 ROWS -- Linha de início: Vai começar a retornar a partir da linha 40 FETCH NEXT 10 ROWS ONLY -- Quantidade de linhas para retornar: Vai retornar as próximas 10 linhas |
Resultado:
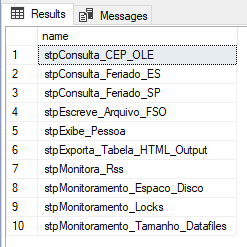
Caso você queira saber mais sobre esse recurso, não deixe de visitar o meu artigo SQL Server – Como criar paginação de dados nos resultados de uma consulta com OFFSET e FETCH
Sequences
Visualizar conteúdoExemplo clássico: Tabelas Pessoa_Fisica e Pessoa_Juridica. Caso você utilize IDENTITY para gerar um sequencial, as 2 tabelas terão um registro com o ID = 25, por exemplo. Caso você utilize uma sequence única para controlar o ID dessas duas tabelas, o ID = 25 só existirá em uma das duas tabelas, funcionando assim:
Código-fonte do teste
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
CREATE SEQUENCE dbo.[seq_Pessoa] AS [INT] START WITH 1 INCREMENT BY 1 MINVALUE 1 MAXVALUE 999999999 CYCLE CACHE GO CREATE TABLE dbo.Pessoa_Fisica ( Id INT DEFAULT NEXT VALUE FOR dbo.seq_Pessoa, Nome VARCHAR(100), CPF VARCHAR(11) ) CREATE TABLE dbo.Pessoa_Juridica ( Id INT DEFAULT NEXT VALUE FOR dbo.seq_Pessoa, Nome VARCHAR(100), CNPJ VARCHAR(14) ) INSERT INTO dbo.Pessoa_Fisica (Nome, CPF) VALUES('Dirceu Resende', '11111111111') INSERT INTO dbo.Pessoa_Juridica (Nome, CNPJ) VALUES('Dirceu Resende Ltda', '22222222222222') INSERT INTO dbo.Pessoa_Fisica (Nome, CPF) VALUES('Dirceu Resende 2', '33333333333') INSERT INTO dbo.Pessoa_Juridica (Nome, CNPJ) VALUES('Dirceu Resende ME', '44444444444444') SELECT * FROM dbo.Pessoa_Fisica SELECT * FROM dbo.Pessoa_Juridica |
Resultado
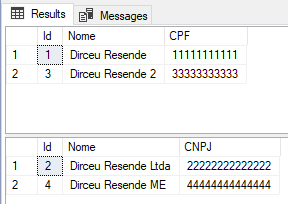
Caso você queira saber mais sobre as Sequences no SQL Server, leia o meu artigo SQL Server 2012 – Trabalhando com Sequences e comparações com IDENTITY.
Tratamento de erros e exceções com o THROW
Visualizar conteúdoFunção lógica – IIF
Visualizar conteúdoFunção lógica – CHOOSE
Visualizar conteúdoExemplo de uso:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT CHOOSE(5, 'Janeiro', 'Fevereiro', 'Março', 'Abril', 'Maio', 'Junho', 'Julho', 'Agosto', 'Setembro', 'Novembro', 'Dezembro' ) |
Resultado:
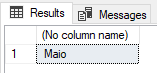
Outro exemplo, agora recuperando o índice a partir do resultado de uma função:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
SELECT GETDATE() AS Hoje, DATEPART(WEEKDAY, GETDATE()) AS Dia_Semana, CHOOSE(DATEPART(WEEKDAY, GETDATE()), 'Domingo', 'Segunda-feira', 'Terça-feira', 'Quarta-feira', 'Quinta-feira', 'Sexta-feira', 'Sábado' ) AS Nome_Dia_Semana |
Resultado:

Exemplos utilizando índices fora da lista e índices com decimais
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
SELECT CHOOSE(-1, 'Domingo', 'Segunda-feira', 'Terça-feira', 'Quarta-feira', 'Quinta-feira', 'Sexta-feira', 'Sábado' ) AS Nome_Dia_Semana1, CHOOSE(4.9, 'Domingo', 'Segunda-feira', 'Terça-feira', 'Quarta-feira', 'Quinta-feira', 'Sexta-feira', 'Sábado' ) AS Nome_Dia_Semana2 |
Resultado:
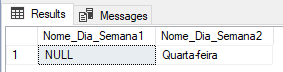
Como podemos ver acima, quando o índice da função CHOOSE não está no intervalo da lista, a função irá retornar NULL. E quando utilizamos um índice com casas decimais, o índice será convertido (truncado) para um número inteiro.
Observação: Internamente, o CHOOSE é um atalho para o CASE, então os 2 tem o mesmo desempenho no que se refere à performance.
Funções de conversão – PARSE, TRY_PARSE, TRY_CONVERT e TRY_CAST
Visualizar conteúdoA função PARSE (disponível para datas e números) é muito útil para conversões de alguns formatos diferentes do padrão, que o CAST e o CONVERT não conseguem converter, como o exemplo abaixo:
|
1 2 3 4 5 6 7 8 |
SELECT CAST('Sábado, 29 de dezembro de 2018' AS DATETIME) AS [Cast] -- Erro GO SELECT CONVERT(DATETIME, 'Sábado, 29 de dezembro de 2018') AS [CONVERT] -- Erro GO SELECT PARSE('Sábado, 29 de dezembro de 2018' AS DATETIME USING 'pt-BR') AS [PARSE] -- Sucesso GO |
Resultado:
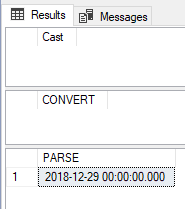
Como evolução da função PARSE, temos a função TRY_PARSE, que possui basicamente o mesmo comportamento da função PARSE, mas com o diferencial que quando a conversão não é possível, ao invés de retornar uma exceção durante o processamento, vai apenas retornar NULL.
Exemplo:
|
1 2 3 4 5 6 7 8 |
-- Nesse exemplo, será gerada uma exceção durante a execução do código T-SQL -- Msg 9819, Level 16, State 1, Line 1: Error converting string value 'Domingo, 29 de dezembro de 2018' into data type datetime using culture 'pt-BR'. SELECT PARSE('Domingo, 29 de dezembro de 2018' AS DATETIME USING 'pt-BR') AS [PARSE] GO -- Aqui vai apenas retornar NULL SELECT TRY_PARSE('Domingo, 29 de dezembro de 2018' AS DATETIME USING 'pt-BR') AS [PARSE] GO |
A mesma coisa ocorre com as funções TRY_CONVERT e TRY_CAST, que possuem o mesmo comportamento das funções originais, mas não geram exceção ao não conseguir realizar uma conversão.
Exemplos de uso:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
-- Sucesso (2018-12-28 00:00:00.000) SELECT CAST('2018-12-28' AS DATETIME) GO -- Erro: The conversion of a varchar data type to a datetime data type resulted in an out-of-range value. SELECT CAST('2018-12-99' AS DATETIME) GO -- NULL SELECT TRY_CAST('2018-12-99' AS DATETIME) GO -- Sucesso (2018-12-28 00:00:00.000) SELECT CONVERT(DATETIME, '2018-12-28') GO -- Erro: The conversion of a varchar data type to a datetime data type resulted in an out-of-range value. SELECT CONVERT(DATETIME, '2018-12-99') GO -- NULL SELECT TRY_CONVERT(DATETIME, '2018-12-99') GO |
Resultado:
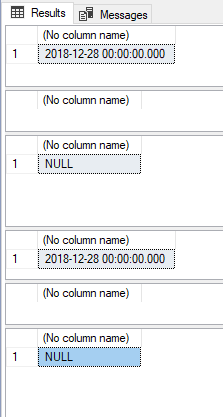
Para saber mais sobre tratamentos de dados e conversões, veja o meu artigo SQL Server – Como identificar erros de conversão de dados utilizando TRY_CAST, TRY_CONVERT, TRY_PARSE, ISNUMERIC e ISDATE.
Função de data – EOMONTH
Visualizar conteúdoExemplos de uso
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT EOMONTH('2018-01-01') AS Janeiro, EOMONTH('2018-02-12') AS Fevereiro, EOMONTH('2018-03-15') AS [Março], EOMONTH('2018-04-17') AS Abril, EOMONTH('2018-05-29') AS Maio, EOMONTH('2018-06-05') AS Junho, EOMONTH('2018-07-04') AS Julho, EOMONTH('2018-08-24') AS Agosto, EOMONTH('2018-09-21') AS Setembro, EOMONTH('2018-10-11') AS Outubro, EOMONTH('2018-11-10') AS Novembro, EOMONTH('2018-12-03') AS Dezembro |
Resultado

Funções de data – DATEFROMPARTS, DATETIME2FROMPARTS, DATETIMEFROMPARTS, DATETIMEOFFSETFROMPARTS, SMALLDATETIMEFROMPARTS e TIMEFROMPARTS
Visualizar conteúdo- DATEFROMPARTS ( year, month, day)
- DATETIME2FROMPARTS ( year, month, day, hour, minute, seconds, fractions, precision )
- DATETIMEFROMPARTS ( year, month, day, hour, minute, seconds, milliseconds )
- DATETIMEOFFSETFROMPARTS ( year, month, day, hour, minute, seconds, fractions, hour_offset, minute_offset, precision )
- SMALLDATETIMEFROMPARTS ( year, month, day, hour, minute )
- TIMEFROMPARTS ( hour, minute, seconds, fractions, precision )
Script para geração dos dados de teste:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
IF (OBJECT_ID('tempdb..#Dados') IS NOT NULL) DROP TABLE #Dados CREATE TABLE #Dados ( Ano INT, Mes INT, Dia INT, Hora INT, Minuto INT, Segundo INT, Millisegundo INT, Offset_Hora INT, Offset_Minuto INT ) INSERT INTO #Dados VALUES (2018, 12, 19, 14, 39, 1, 123, 3, 30), (1987, 5, 28, 21, 22, 59, 999, 3, 0), (2018, 12, 31, 23, 59, 59, 999, 0, 0) |
Exemplo da função DATEFROMPARTS e como fazíamos isso antes do SQL Server 2012:
|
1 2 3 4 5 6 7 8 9 10 11 |
-- Antes do SQL Server 2012: Utilizando CAST/CONVERT SELECT CAST(CAST(Ano AS VARCHAR(4)) + '-' + CAST(Mes AS VARCHAR(2)) + '-' + CAST(Dia AS VARCHAR(2)) AS DATE) AS [CAST_DATE] FROM #Dados -- A partir do SQL Server 2012: DATEFROMPARTS SELECT DATEFROMPARTS (Ano, Mes, Dia) AS [DATEFROMPARTS] FROM #Dados |
Resultado:

Exemplo utilizando as 6 funções juntas
|
1 2 3 4 5 6 7 8 9 |
SELECT DATEFROMPARTS (Ano, Mes, Dia) AS [DATEFROMPARTS], DATETIME2FROMPARTS (Ano, Mes, Dia, Hora, Minuto, Segundo, Millisegundo, 7) AS [DATETIME2FROMPARTS], DATETIMEFROMPARTS (Ano, Mes, Dia, Hora, Minuto, Segundo, Millisegundo) AS [DATETIMEFROMPARTS], DATETIMEOFFSETFROMPARTS (Ano, Mes, Dia, Hora, Minuto, Segundo, Millisegundo, Offset_Hora, Offset_Minuto, 7) AS [DATETIMEOFFSETFROMPARTS], SMALLDATETIMEFROMPARTS (Ano, Mes, Dia, Hora, Minuto) AS [SMALLDATETIMEFROMPARTS], TIMEFROMPARTS (Hora, Minuto, Segundo, Millisegundo, 7) AS [TIMEFROMPARTS] FROM #Dados |
Resultado:

Função de tratamento de string – FORMAT
Visualizar conteúdoAlguns exemplos do uso de FORMAT – Números
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
SELECT FORMAT(123456.99, 'C'), -- Formato de moeda padrão FORMAT(-123456.987654321, 'C4'), -- Formato de moeda com 4 casas decimais FORMAT(123456.987654321, 'C2', 'pt-br') -- Formato de moeda forçando a localidade pra Brasil e 2 casas decimais SELECT FORMAT(123456.99, 'D'), -- Formato de número inteiro com valores numeric (NULL) FORMAT(123456, 'D'), -- Formato de número inteiro FORMAT(-123456, 'D4'), -- Formato de número inteiro com valores negativos FORMAT(123456, 'D10', 'pt-br'), -- formato de número inteiro com tamanho fixo em 10 caracteres FORMAT(-123456, 'D10', 'pt-br') -- formato de número inteiro com tamanho fixo em 10 caracteres SELECT FORMAT(123456.99, 'E'), -- Formato de notação científica FORMAT(123456.99, 'E4') -- Formato de notação científica e 4 casas decimais de precisão SELECT FORMAT(1, 'P'), -- Formato de porcentagem FORMAT(1, 'P2'), -- Formato de porcentagem com 2 casas decimais FORMAT(0.91, 'P'), -- Formato de porcentagem FORMAT(0.005, 'P4') -- Formato de porcentagem com 4 casas decimais SELECT FORMAT(255, 'X'), -- Formato hexadecimal FORMAT(512, 'X8') -- Formato hexadecimal fixando o retorno em 8 caracteres |
Resultado
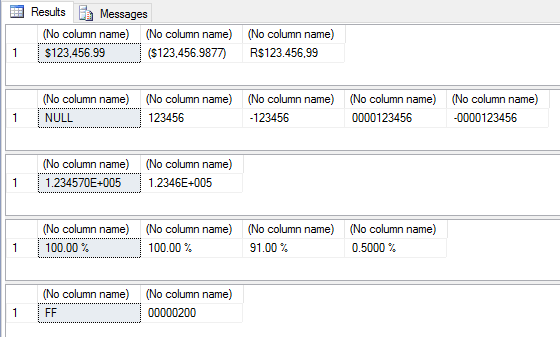
Outros exemplos com números:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
SELECT -- Formato de moeda brasileira (manualmente) FORMAT(123456789.9, 'R$ ###,###,###,###.00'), -- Utilizando sessão (;) para formatar valores positivos e negativos FORMAT(123456789.9, 'R$ ###,###,###,###.00;-R$ ###,###,###,###.00'), -- Utilizando sessão (;) para formatar valores positivos e negativos FORMAT(-123456789.9, 'R$ ###,###,###,###.00;-R$ ###,###,###,###.00'), -- Utilizando sessão (;) para formatar valores positivos e negativos FORMAT(-123456789.9, 'R$ ###,###,###,###.00;(R$ ###,###,###,###.00)'), -- Formatando porcentagem com 2 casas decimais FORMAT(0.9975, '#.00%'), -- Formatando porcentagem com 4 casas decimais FORMAT(0.997521654, '#.0000%'), -- Formatando porcentagem com 4 casas decimais FORMAT(123456789.997521654, '#.0000%'), -- Formatando porcentagem com 2 casas decimais e utilizando sessão (;) FORMAT(0.123456789, '#.00%;-#.00%'), -- Formatando porcentagem com 2 casas decimais e utilizando sessão (;) FORMAT(-0.123456789, '#.00%;-#.00%'), -- Formatando porcentagem com 2 casas decimais e utilizando sessão (;) FORMAT(-0.123456789, '#.00%;(#.00%)') |
Resultado:

Preenchendo número com zeros à esquerda:
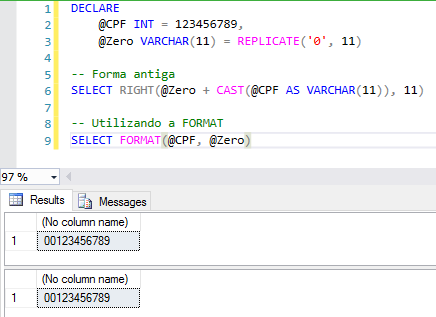
Alguns exemplos do uso de FORMAT – Datas
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
SET LANGUAGE 'English' SELECT FORMAT(GETDATE(), 'd'), -- Padrão de data abreviada. FORMAT(GETDATE(), 'D'), -- Padrão de data completa. FORMAT(GETDATE(), 'R'), -- Padrão RFC1123 FORMAT(GETDATE(), 't'), -- Padrão de hora abreviada. FORMAT(GETDATE(), 'T') -- Padrão de hora completa. SET LANGUAGE 'Brazilian' SELECT FORMAT(GETDATE(), 'd'), -- Padrão de data abreviada. FORMAT(GETDATE(), 'D'), -- Padrão de data completa. FORMAT(GETDATE(), 'R'), -- Padrão RFC1123 FORMAT(GETDATE(), 't'), -- Padrão de hora abreviada. FORMAT(GETDATE(), 'T') -- Padrão de hora completa. |
Resultado:

Formatação personalizada de Data:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
SELECT -- Formato de data típico do Brasil FORMAT(GETDATE(), 'dd/MM/yyyy'), -- Formato de data/hora típico dos EUA FORMAT(GETDATE(), 'yyyy-MM-dd HH:mm:ss.fff'), -- Exibindo a data por extenso FORMAT(GETDATE(), 'dddd, dd \d\e MMMM \d\e yyyy'), -- Exibindo a data por extenso (forçando o idioma pra PT-BR) FORMAT(GETDATE(), 'dddd, dd \d\e MMMM \d\e yyyy', 'pt-br'), -- Exibindo a data/hora, mas zerando os minutos e segundos FORMAT(GETDATE(), 'dd/MM/yyyy HH:00:00', 'pt-br') |
Resultado:

Se quiser saber mais sobre a função FORMAT, leia o meu artigo SQL Server – Utilizando a função FORMAT para aplicar máscaras e formatações em números e datas.
Função de tratamento de string – CONCAT
Visualizar conteúdoGeração dos dados para os exemplos
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
IF (OBJECT_ID('tempdb..#Dados') IS NOT NULL) DROP TABLE #Dados CREATE TABLE #Dados ( Dt_Nascimento DATE, Nome1 VARCHAR(50), Nome2 VARCHAR(50), Idade AS CONVERT(INT, (DATEDIFF(DAY, Dt_Nascimento, GETDATE()) / 365.25)) ) INSERT INTO #Dados VALUES ('1987-05-28', 'Dirceu', 'Resende'), ('1987-01-15', 'Patricia', 'Resende'), ('1987-01-15', 'Teste', NULL) |
Exemplos
|
1 2 3 4 5 6 7 8 9 10 11 |
-- Antes do SQL Server 2012: Utilizando CAST/CONVERT SELECT Nome1 + ' ' + Nome2 + ' | ' + CAST(Idade AS VARCHAR(3)) + ' | ' + CAST(Dt_Nascimento AS VARCHAR(40)) AS [Antes do SQL Server 2012] FROM #Dados -- A partir do SQL Server 2012: Utilizando CONCAT SELECT CONCAT(Nome1, ' ', Nome2, ' | ', Idade, ' | ', Dt_Nascimento) AS [A partir do SQL Server 2012] FROM #Dados |
Resultado:

Como vocês podem observar, a função CONCAT faz a conversão dos tipos de dados para varchar automaticamente e ainda faz o tratamento de valores NULL e os converte para strings vazias. Ou seja, mais simples, o CONCAT é, mas e a performance? Como fica ?

Pelo menos nos testes que eu fiz, o CONCAT se mostrou mais rápido que a concatenação tradicional (utilizando “+”). Mais simples e mais rápido.
Funções analíticas – FIRST_VALUE e LAST_VALUE
Visualizar conteúdoScript T-SQL para a criação dos dados para o exemplo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
IF (OBJECT_ID('tempdb..#Dados') IS NOT NULL) DROP TABLE #Dados CREATE TABLE #Dados ( Id INT IDENTITY(1,1), Nome VARCHAR(50), Idade INT ) INSERT INTO #Dados VALUES ('Dirceu Resende', 31), ('Joãozinho das Naves', 33), ('Rafael Sudré', 48), ('Potássio', 27), ('Rafaela', 25), ('Jodinei', 39) |
Exemplo 1 – Identificando a maior e menor idade e o nome dessas pessoas
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
-- Antes do SQL Server 2012: MIN/MAX e Subquery SELECT *, (SELECT MIN(Idade) FROM #Dados) AS Menor_Idade, (SELECT MAX(Idade) FROM #Dados) AS Maior_Idade, (SELECT TOP(1) Nome FROM #Dados ORDER BY Idade) AS Nome_Menor_Idade, (SELECT TOP(1) Nome FROM #Dados ORDER BY Idade DESC) AS Nome_Maior_Idade FROM #Dados -- A partir do SQL Server 2012: FIRST_VALUE SELECT *, FIRST_VALUE(Idade) OVER(ORDER BY Idade) AS Menor_Idade, FIRST_VALUE(Idade) OVER(ORDER BY Idade DESC) AS Maior_Idade, FIRST_VALUE(Nome) OVER(ORDER BY Idade) AS Nome_Menor_Idade, FIRST_VALUE(Nome) OVER(ORDER BY Idade DESC) AS Nome_Maior_Idade FROM #Dados |
Resultado:
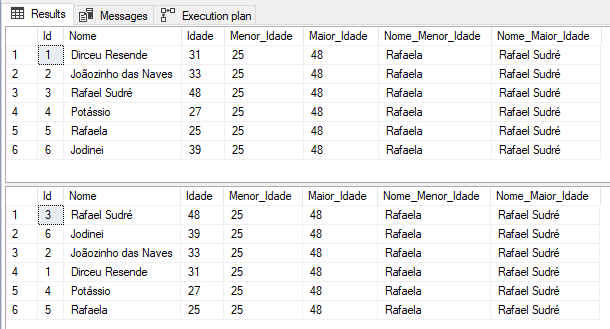
Bem, o código ficou bem mais simples e limpo. Falando em performance, existem várias formas de atingir esse objetivo, com consultas mais performáticas que a que utilizei no primeiro exemplo, mas quis colocar o código mais simples possível. Se você realmente utiliza esse tipo de programação no seu código, é bom revisar suas consultas, pois elas tem uma performance bem ruim.
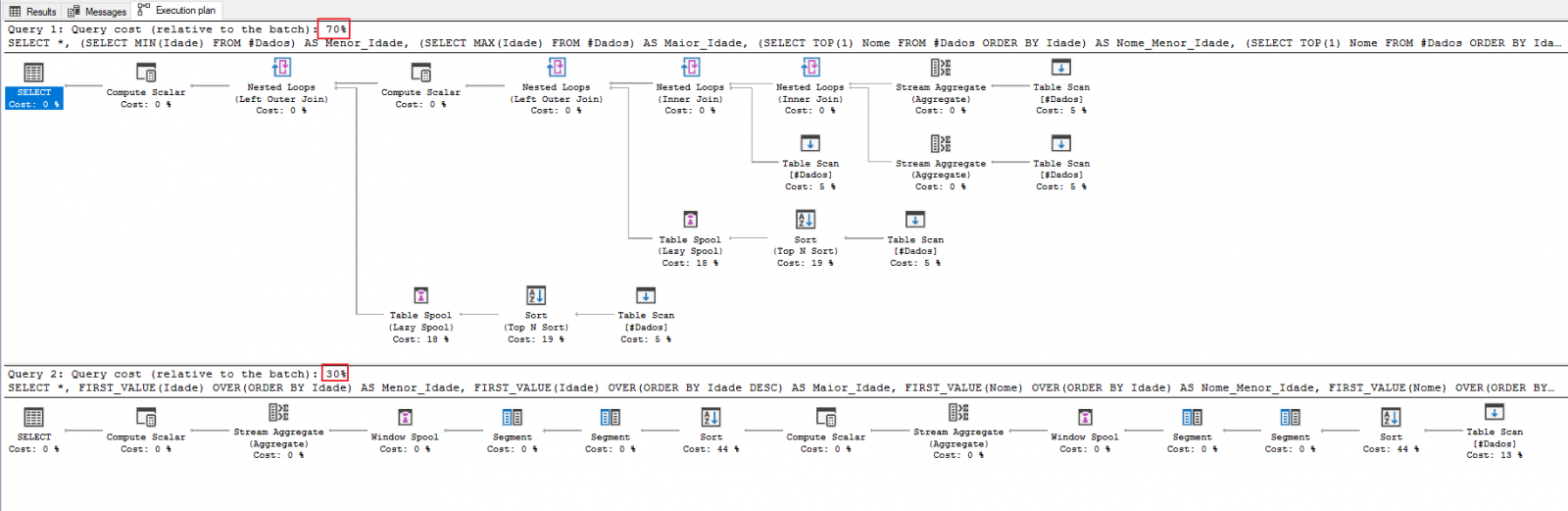
Veja como é o plano de execução da primeira consulta e da consulta utilizando a função FIRST_VALUE:
E agora vamos utilizar a função LAST_VALUE para retornar os maiores registros do conjunto de dados:
|
1 2 3 4 5 6 7 8 |
SELECT *, FIRST_VALUE(Idade) OVER(ORDER BY Idade) AS Menor_Idade, LAST_VALUE(Idade) OVER(ORDER BY Idade) AS Maior_Idade, FIRST_VALUE(Nome) OVER(ORDER BY Idade) AS Nome_Menor_Idade, LAST_VALUE(Nome) OVER(ORDER BY Idade) AS Nome_Maior_Idade FROM #Dados |
Resultado:

Ué.. A função LAST_VALUE não trouxe o último valor e sim o valor da linha atual.. Isso acontece devido ao conceito de frame. O frame permite que você especifique um conjunto de linhas para a “janela”, que é ainda menor que a partição. O frame padrão contém as linhas que começam com a primeira linha e até a linha atual. Para a linha 1, a “janela” é apenas linha 1. Para a linha 3, a janela contém as linhas 1 a 3. Ao usar FIRST_VALUE, a primeira linha é incluída por padrão, para que você não precise se preocupar com isso para obter os resultados esperados.
Para que a função LAST_VALUE retorne realmente o último valor de todo o conjunto de dados, vamos utilizar os parâmetros ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING junto com a função LAST_VALUE, o que faz com que a janela inicie na linha atual até a última linha da partição.
Novo script utilizando a função LAST_VALUE:
|
1 2 3 4 5 6 7 8 |
SELECT *, FIRST_VALUE(Idade) OVER(ORDER BY Idade) AS Menor_Idade, LAST_VALUE(Idade) OVER(ORDER BY Idade ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS Maior_Idade, FIRST_VALUE(Nome) OVER(ORDER BY Idade) AS Nome_Menor_Idade, LAST_VALUE(Nome) OVER(ORDER BY Idade ROWS BETWEEN CURRENT ROW AND UNBOUNDED FOLLOWING) AS Nome_Maior_Idade FROM #Dados |
Resultado:
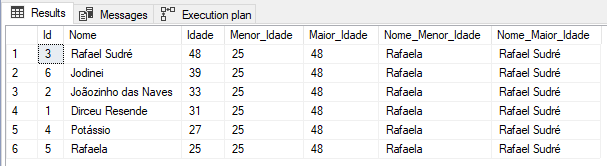
Funções analíticas – LAG e LEAD
Visualizar conteúdoScript T-SQL para gerar os dados de teste:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
IF (OBJECT_ID('tempdb..#Dados') IS NOT NULL) DROP TABLE #Dados CREATE TABLE #Dados ( Id INT IDENTITY(1,1), Nome VARCHAR(50), Idade INT ) INSERT INTO #Dados VALUES ('Dirceu Resende', 31), ('Joãozinho das Naves', 33), ('Rafael Sudré', 48), ('Potássio', 27), ('Rafaela', 25), ('Jodinei', 39) |
Imaginem que eu queira criar um ponteiro e acessar quem é o próximo ID e o ID anterior ao registro atual. Antes do SQL Server 2008, precisaríamos criar self-joins para completar essa tarefa. A partir do SQL Server 2012, podemos utilizar as funções LAG e LEAD para essa necessidade:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
-- Antes do SQL Server 2008: Self-Joins SELECT A.*, B.Id AS Id_Proximo, C.Id AS Id_Anterior FROM #Dados A LEFT JOIN #Dados B ON B.Id = A.Id + 1 LEFT JOIN #Dados C ON C.Id = A.Id - 1 -- A partir do SQL Server 2012: LAG e LEAD SELECT A.*, LEAD(Id) OVER(ORDER BY Id) AS Id_Proximo, LAG(Id) OVER(ORDER BY Id) AS Id_Anterior FROM #Dados A |
Resultado:
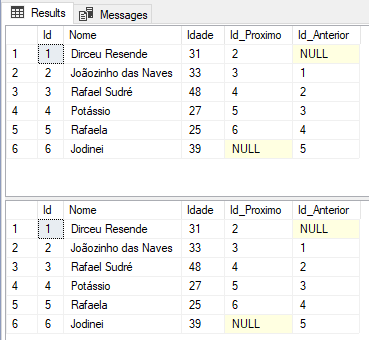
Código bem mais simples e limpo. Vamos analisar a performance das duas consultas agora:

É, embora o LAG e o LEAD sejam bem mais simples e legíveis, a performance deles acaba sendo um pouco abaixo dos Self-Joins, provavelmente devido à ordenação que é feita para aplicar as funções. Vou inserir um volume maior de registros (3 milhões de registros) para verificar se a performance continua sendo pior que os Self-Joins, a qual eu acredito não fazer sentido, já que o Self-Join realiza várias leituras na tabela e as funções, em teoria, deveriam fazer apenas 1.
Resultados dos testes com 3 milhões de registros (me surpreenderam):
![]()
Plano de execução com SELF-JOIN:

Plano de execução com LED e LEAD:

Imaginei que por ter um plano mais simples e fazer menor leituras na tabela, as funções teriam um desempenho bem melhor que os self-joins, mas por causa de um operador de SORT bem pesado, a performance utilizando as funções acabou sendo pior, conforme podemos observar no plano de execução e no warning do operador sort:
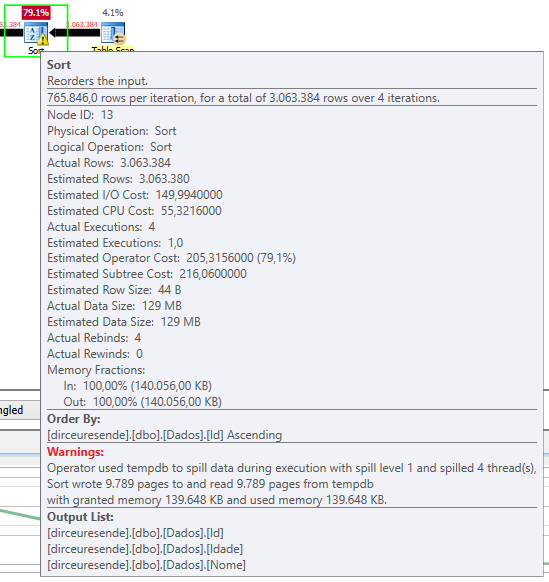
Em resumo, se for trabalhar com pequenos conjuntos de dados, pode usar as funções LAG e LEAD tranquilamente, pois o código fica mais legível. Caso precise utilizar isso em grandes volumes de dados, teste o self-join para avaliar como será a performance no seu cenário.
EXECUTE… WITH RESULT SETS
Visualizar conteúdoA partir do SQL Server 2012, agora podemos utilizar a cláusula WITH RESULT SETS na execução de Stored Procedures, de modo que podemos mudar o nome e o tipo dos campos retornados por Stored Procedures, de forma muito simples e prática.
Exemplo 1:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
CREATE PROCEDURE dbo.stpLista_Tabelas AS BEGIN SELECT [object_id], [name], [type_desc], create_date FROM sys.tables END -- Executa a Stored Procedure EXEC dbo.stpLista_Tabelas GO EXEC dbo.stpLista_Tabelas WITH RESULT SETS (( [id_tabela] int, [nome_tabela] varchar(100), [tipo] varchar(50), [data_criacao] date )) |
Resultado:
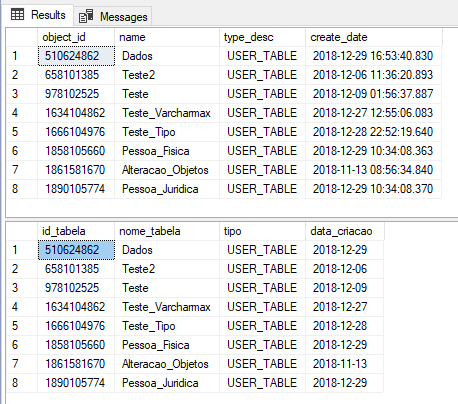
Caso a Stored Procedure retorne mais de um conjunto de dados, você pode utilizar a cláusula WITH RESULT SETS dessa forma:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
CREATE PROCEDURE dbo.stpLista_Tabelas2 AS BEGIN SELECT [object_id], [name], [type_desc], create_date FROM sys.tables SELECT [object_id], [name], [type_desc], create_date FROM sys.objects END -- Executa a Stored Procedure EXEC dbo.stpLista_Tabelas2 GO EXEC dbo.stpLista_Tabelas2 WITH RESULT SETS ( ( [id_tabela] int, [nome_tabela] varchar(100), [tipo] varchar(50), [data_criacao] date ), ( [id_objeto] int, [nome_objeto] varchar(100), [tipo] varchar(50), [data_criacao] date ) ) |
Resultado:
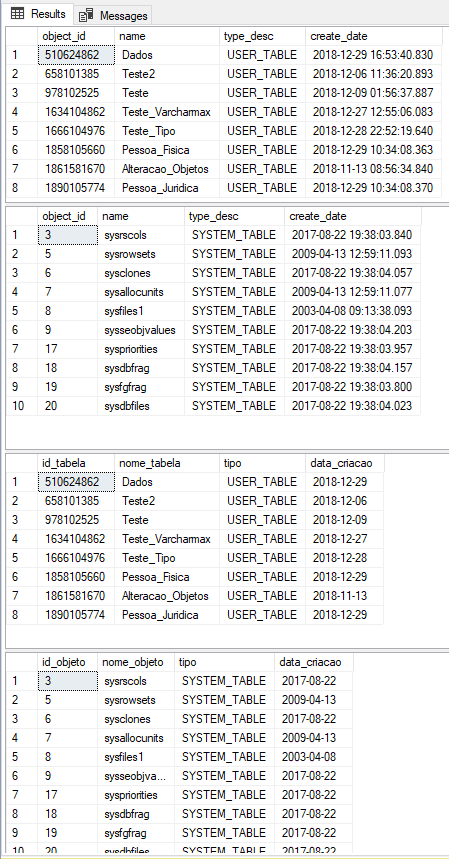
SELECT TOP X PERCENT
Visualizar conteúdoA sua utilização é praticamente igual ao tradicional e já conhecido TOP:
|
1 2 3 4 5 6 7 8 |
-- Conta quantos objetos existem na sys.objects (121) SELECT COUNT(*) FROM sys.objects -- Retorna 10 linhas da view sys.objects SELECT TOP 10 * FROM sys.objects -- Retorna 10% das linhas da view sys.objects (arredondando para cima - CEILING) SELECT TOP 10 PERCENT * FROM sys.objects |
Resultado:
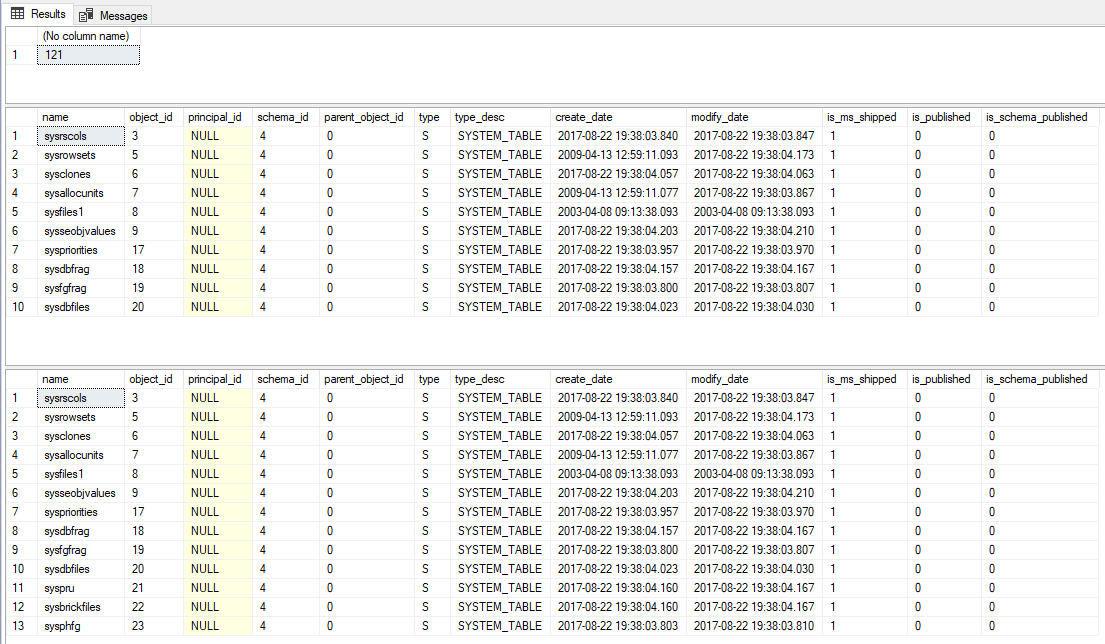
Função matemática – LOG
Visualizar conteúdoÉ isso aí, pessoal!
Um grande abraço pra vocês e até o próximo post.

