
Hey Guys!
Boa noite!
Hoje me deparei com um problema crítico de performance em um ambiente de produção, onde uma determinada query (que pode ser executada várias vezes por segundo) estava apresentando um problema de lentidão (demorava entre 21 e 30 segundos por execução) já antigo e conhecido, mas que hoje foi o dia de resolver isso de uma vez por todas.
Para muitos DBA’s (inclusive para mim) e entusiastas de modelagem de banco de dados, esse tipo de problema não deveria ocorrer nunca, mas infelizmente na prática não é o que acontece. Analisando a query, que por sinal era bem grande, com vários CASES, LEFT JOIN’S, OR’s, uso de função, etc pude observar que haviam muitos casos de conversão implícita e ao analisar o plano real de execução, foi bem claro o motivo da lentidão:
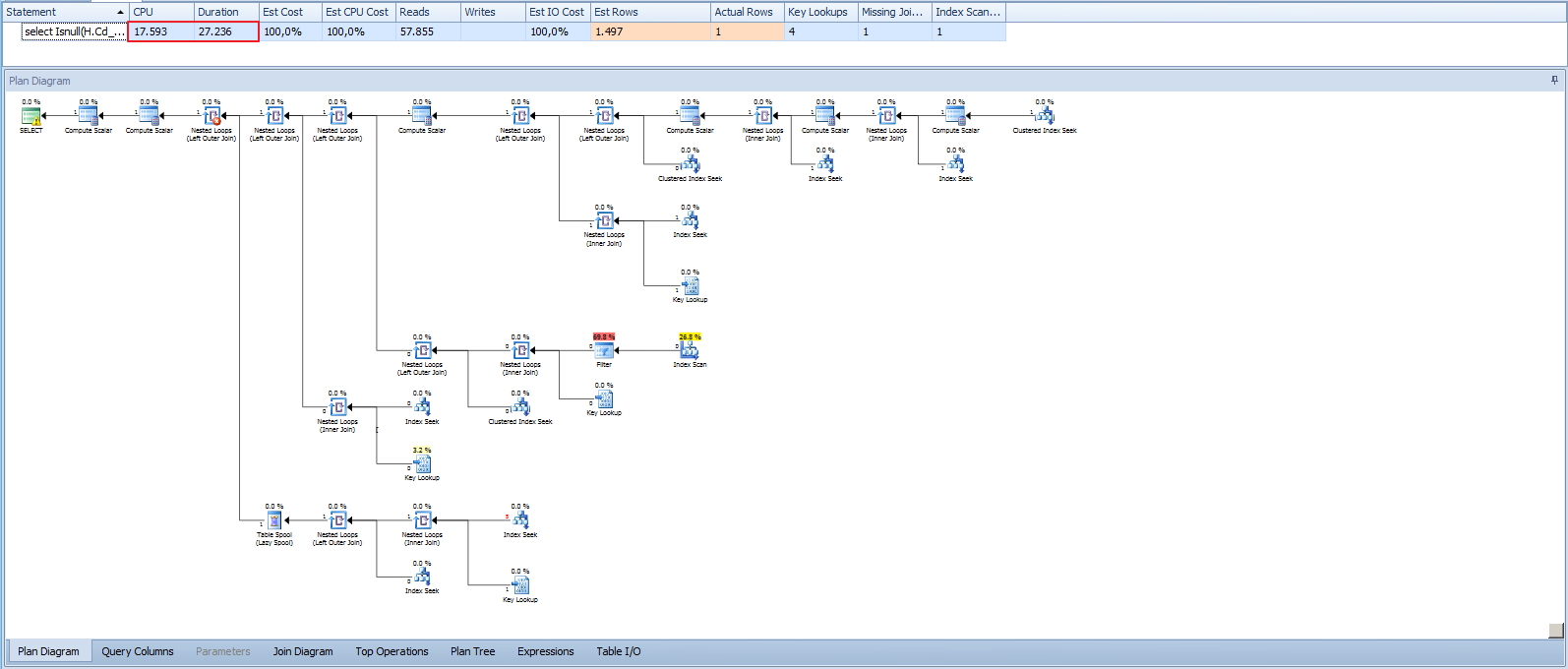
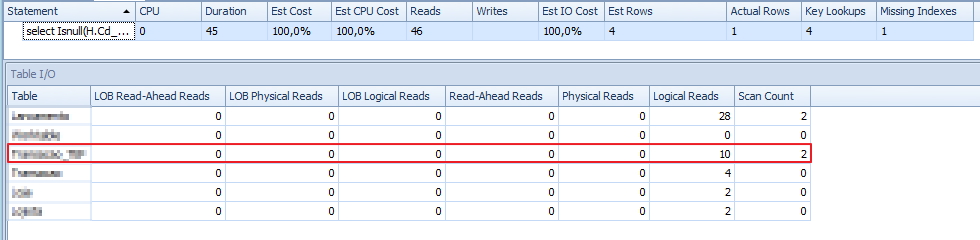
Analisando as leituras em disco, podemos observar que as leituras em uma tabela específica estão bem altas, principalmente se levarmos em conta que a query utiliza na cláusula WHERE um termo de igualdade na tabela principal da consulta, informando um código que é chave primária e está no índice clustered, ou seja, deveria ser uma consulta extremamente rápida e otimizada, processando poucos registros.
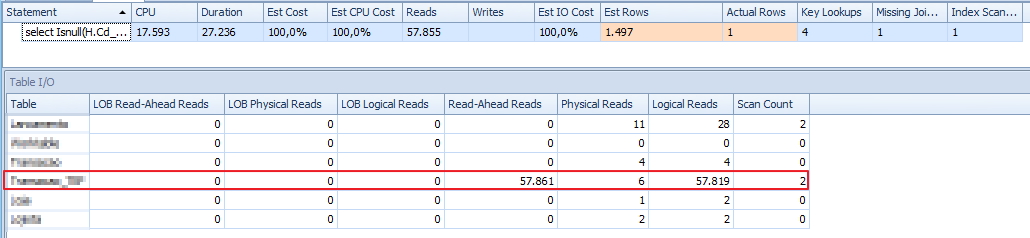
Raparem que há um warning no select. E ao posicionar o mouse sobre ele, podemos visualizar essas informações:
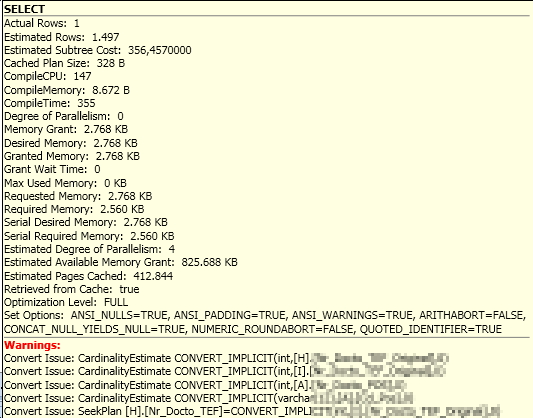
Bom, temos o problema de conversão implícita ocorrendo. Isso ocorre quando duas colunas de tipos de dados diferentes são comparadas e aí o banco precisa converter isso manualmente durante a consulta.
Analisando os JOINS da consulta, pude observar que as colunas envolvidas na comparação eram de tipos diferentes. Isso faz com que todos os registros envolvidos no JOIN tenham que ser convertidos para o mesmo tipo, para depois verificar se eles devem ser restringidos pelas cláusulas no JOIN ou não. Se o volume de registros for muito alto, isso pode aumentar consideravelmente o tempo de processamento e leituras em disco (como demonstrado no exemplo)
Um simples comando de ALTER TABLE na coluna que estava realizando o JOIN da tabela que estava com muitas leituras para igualar os tipos de dados resolveu o problema:
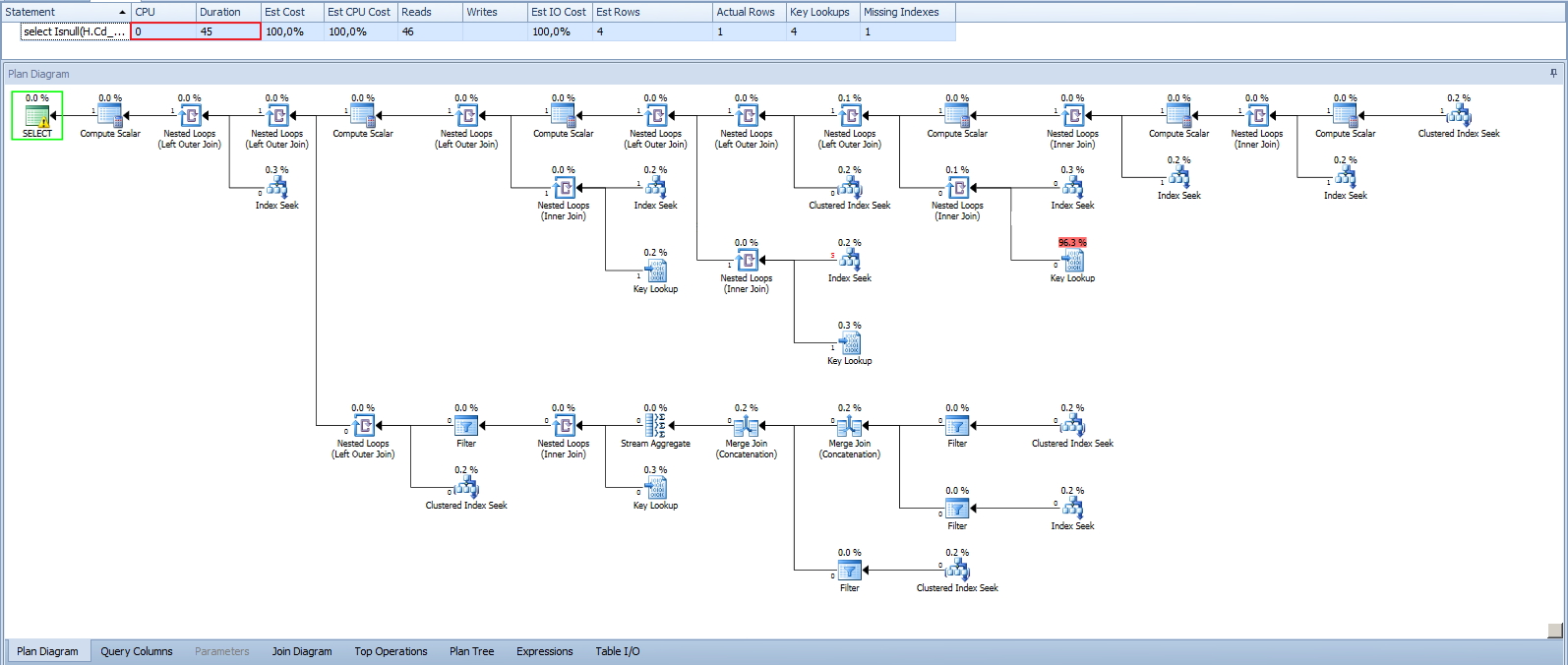
Uma outra solução seria criar uma tabela intermediária contendo uma parte da query, e convertendo a coluna já para o tipo correto. Com essa tabela intermediária é que seria realizado o JOIN com o restante da query, e agora, com o mesmo tipo de dado, não havia mais o problema de conversão implícita e a query estaria sendo executada de forma mais otimizada.
And that's it, folks!
Um abraço e até o próximo post!

Ótimo artigo! Obrigada!
Ei!
Que bom que você gostou e espero ter ajudado