
Fala galera!
Tudo bem com vocês ?
Nesse post rápido vou demonstrar a vocês como identificar as ocorrências de um caractere específico numa string ou tabela ou seja, contar quantas vezes o caractere “X” aparece em cada linha de uma tabela.
Para os exemplos abaixo, vou utilizar 2 SP’s do CLR que eu demonstrei como criar (além de outras alternativas, para os que não querem utilizar CLR) nos artigos abaixo:
- SQL Server – Como exportar e importar arquivos com dados tabulares (Ex: CSV) utilizando o CLR (C#)
- Importando arquivos CSV para o banco de dados SQL Server
- SQL Server – Como importar arquivos de texto para o banco (OLE Automation, CLR, BCP, BULK INSERT, OPENROWSET)
Hoje eu tive um problema ao importar um arquivo CSV de mais de 40 mil linhas e a rotina, que há bastante tempo é executada diariamente e sem apresentar problemas, retornou a mensagem de erro abaixo.
|
1 2 3 4 5 6 7 8 9 |
IF (OBJECT_ID('tempdb..##Saida') IS NOT NULL) DROP TABLE ##Saida EXEC CLR.dbo.stpImporta_CSV @Ds_Caminho_Arquivo = N'C:\Users\difil\Desktop\Teste.csv', -- nvarchar(max) @Ds_Separador = N'|', -- nvarchar(max) @Fl_Primeira_Linha_Cabecalho = 0, -- bit @Nr_Linha_Inicio = 0, -- int @Nr_Linhas_Retirar_Final = 0, -- int @Ds_Tabela_Destino = N'##Saida', -- nvarchar(max) @Ds_Codificacao = N'utf-8' -- nvarchar(max) |
Msg 6522, Level 16, State 1, Procedure stpImporta_CSV, Line 0 [Batch Start Line 0]
A .NET Framework error occurred during execution of user-defined routine or aggregate “stpImporta_CSV”:
System.ApplicationException: Erro : A matriz de entrada é maior do que o número de colunas desta tabela.
ou
Msg 6522, Level 16, State 1, Procedure stpImporta_CSV, Line 0 [Batch Start Line 0] A .NET Framework error occurred during execution of user-defined routine or aggregate “stpImporta_CSV”: System.ApplicationException: Erro : Input array is longer than the number of columns in this table.
Pela descrição do erro, ficou claro que havia algum problema no meu CSV (provavelmente um pipe, que é o meu caractere separador no arquivo, no meio das strings). Pensei em algumas soluções que poderia criar para identificar qual o registro errado, como utilizar cursor, loop while e até que veio uma solução MUITO SIMPLES, rápida e extremamente eficaz: O nosso velho e bom SELECT.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE TABLE #dirceuresende ( Ds_Texto VARCHAR(MAX) ) INSERT INTO #dirceuresende EXEC CLR.dbo.stpImporta_Txt @caminho = N'C:\Users\difil\Desktop\Teste.csv' -- nvarchar(max) SELECT * FROM #dirceuresende |
Exemplo do CSV importado – 2 pipes separando Nome, Idade e E-mail
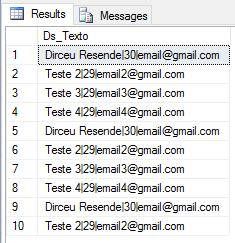
E agora, com a query abaixo, podemos facilmente descobrir quais os registros que estão com a quantidade de pipes diferentes do restante das linhas
|
1 2 3 |
SELECT *, LEN(Ds_Texto) - LEN(REPLACE(Ds_Texto, '|', '')) AS Qt_Pipes FROM #dirceuresende WHERE LEN(Ds_Texto) - LEN(REPLACE(Ds_Texto, '|', '')) != 2 |
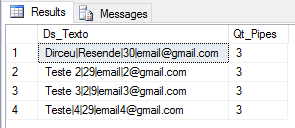
Após isso, é só você alterar o arquivo, corrigir as linhas e importar novamente (e foi o que eu fiz no meu caso, onde apenas 1 linha tinha problema).
O problema do espaço em branco
Em conversa com o Ariel Fernandez, ele me fez lembrar que ao utilizar a função LEN() o SQL Server aplica um RTRIM() na string implicitamente, ou seja, se houver espaços em branco à direita, esses espaços serão cortados no cálculo. Para a maiorias dos casos, isso não terá impactos, mas se o caractere separador que estamos buscando for exatamente o espaço ” “, isso será um problema:
|
1 2 3 |
-- 5 espaços em branco no inicio e no final da string DECLARE @String VARCHAR(100) = N' Dirceu 29 email ' SELECT (LEN(@String) - LEN(REPLACE(@String, ' ', ''))) |
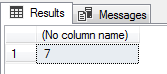
Reparem que a string acima, possui 5 espaços em branco no início e no final da string, além de mais 2 no meio da string que seriam os separadores. Ao aplicar a função LEN(), os 5 caracteres em branco à direita são removidos e o resultado final será 7 ao invés de 12.
Para resolver esse problema, podemos usar a função DATALENGTH, que retorna a quantidade de bytes de uma string (LEN retorna a quantidade de caracteres). Com isso, a nossa query funciona corretamente com o exemplo acima:
|
1 2 3 |
-- 5 espaços em branco no inicio e no final da string DECLARE @String VARCHAR(100) = N' Dirceu 29 email ' SELECT (DATALENGTH(@String) - DATALENGTH(REPLACE(@String, ' ', ''))) |
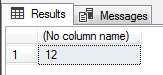
A função DATALENGTH e strings UNICODE
Essa solução parece ter resolvido o nosso problema, mas o DATALENGTH tem uma peculiaridade quando utilizamos dados Unicode (NCHAR, NVARCHAR, etc), pois esses tipos de dados gravam as informações no formato double-byte, ou seja, são necessários 2 bytes para cada caractere da string. Com isso, o resultado da função DATALENGTH acaba ficando dobrado para esses tipos de dados, como demonstro abaixo:
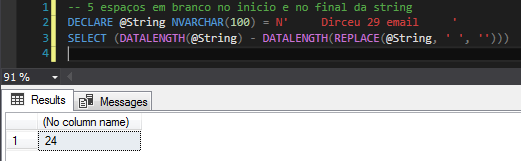
Utilizando a função SQL_VARIANT_PROPERTY para identificar o tipo da variável
Uma solução mais definitiva para isso, seria identificar o tipo de variável de entrada (ou o tipo da coluna) e caso seja do tipo unicode, divide o resultado do datalength por 2. Para conseguir identificar o tipo de dado da nossa variável, vamos utilizar a função SQL_VARIANT_PROPERTY():
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
DECLARE @String NVARCHAR(100) = N' Dirceu 29 email ' SELECT SQL_VARIANT_PROPERTY(@String, 'BaseType') AS [Base Type], SQL_VARIANT_PROPERTY(@String, 'Precision') AS [Precision], SQL_VARIANT_PROPERTY(@String, 'Scale') AS Scale, SQL_VARIANT_PROPERTY(@String, 'Collation') AS Collation, SQL_VARIANT_PROPERTY(@String, 'MaxLength') AS [MaxLength], SQL_VARIANT_PROPERTY(@String, 'TotalBytes') AS TotalBytes DECLARE @String2 VARCHAR(100) = ' Dirceu 29 email ' SELECT SQL_VARIANT_PROPERTY(@String2, 'BaseType') AS [Base Type], SQL_VARIANT_PROPERTY(@String2, 'Precision') AS [Precision], SQL_VARIANT_PROPERTY(@String2, 'Scale') AS Scale, SQL_VARIANT_PROPERTY(@String2, 'Collation') AS Collation, SQL_VARIANT_PROPERTY(@String2, 'MaxLength') AS [MaxLength], SQL_VARIANT_PROPERTY(@String2, 'TotalBytes') AS TotalBytes |
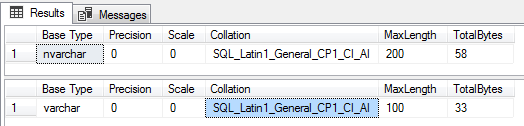
Agora utilizando essa função para a nossa necessidade, podemos utilizá-la para identificar o tipo da variável e realizar o cálculo correto
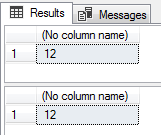
Query avaliando uma string em variável:
|
1 2 3 4 5 6 7 |
-- 5 espaços em branco no inicio e no final da string UNICODE DECLARE @String NVARCHAR(100) = N' Dirceu 29 email ' SELECT (DATALENGTH(@String) - DATALENGTH(REPLACE(@String, ' ', ''))) / (CASE WHEN SQL_VARIANT_PROPERTY(@String, 'BaseType') = 'nvarchar' THEN 2 ELSE 1 END) -- 5 espaços em branco no inicio e no final da string DECLARE @String2 VARCHAR(100) = ' Dirceu 29 email ' SELECT (DATALENGTH(@String2) - DATALENGTH(REPLACE(@String2, ' ', ''))) / (CASE WHEN SQL_VARIANT_PROPERTY(@String2, 'BaseType') = 'nvarchar' THEN 2 ELSE 1 END) |
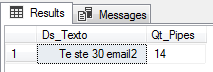
Query utilizando uma string em uma tabela:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
IF (OBJECT_ID('tempdb..#dirceuresende') IS NOT NULL) DROP TABLE #dirceuresende CREATE TABLE #dirceuresende ( Ds_Texto VARCHAR(4000) ) INSERT INTO #dirceuresende VALUES(' Dirceu 29 email '), (' Teste 30 email2 '), (' Te ste 30 email2 ') SELECT *, (DATALENGTH(Ds_Texto) - DATALENGTH(REPLACE(Ds_Texto, ' ', ''))) / (CASE WHEN SQL_VARIANT_PROPERTY(Ds_Texto, 'BaseType') = 'nvarchar' THEN 2 ELSE 1 END) AS Qt_Pipes FROM #dirceuresende WHERE (DATALENGTH(Ds_Texto) - DATALENGTH(REPLACE(Ds_Texto, ' ', ''))) / (CASE WHEN SQL_VARIANT_PROPERTY(Ds_Texto, 'BaseType') = 'nvarchar' THEN 2 ELSE 1 END) != 13 |
Identificando o registro que possui mais espaços que as outras linhas:
Função SQL_VARIANT_PROPERTY e strings com tamanho MAX
Mesmo com a solução acima, ainda temos um possível problema. Se a string ou coluna for do tipo VARCHAR(MAX) ou NVARCHAR(MAX), a função SQL_VARIANT_PROPERTY() apresenta erros ao ser utilizada. Neste caso, a identificação da necessidade de dividir o resultado por 2 ou não, terá que ser feita por você, manualmente.
Exemplo:
|
1 2 3 4 5 6 7 |
-- 5 espaços em branco no inicio e no final da string UNICODE DECLARE @String NVARCHAR(MAX) = N' Dirceu 29 email ' SELECT (DATALENGTH(@String) - DATALENGTH(REPLACE(@String, ' ', ''))) / (CASE WHEN SQL_VARIANT_PROPERTY(@String, 'BaseType') = 'nvarchar' THEN 2 ELSE 1 END) -- 5 espaços em branco no inicio e no final da string DECLARE @String2 VARCHAR(MAX) = ' Dirceu 29 email ' SELECT (DATALENGTH(@String2) - DATALENGTH(REPLACE(@String2, ' ', ''))) / (CASE WHEN SQL_VARIANT_PROPERTY(@String2, 'BaseType') = 'nvarchar' THEN 2 ELSE 1 END) |
Result:
Msg 206, Level 16, State 2, Line 3
Operand type clash: nvarchar(max) is incompatible with sql_variant
Msg 206, Level 16, State 2, Line 7
Operand type clash: varchar(max) is incompatible with sql_variant
Espero que tenham gostado desse post bem simples e rápido e que essa ideia possa lhes ser útil um dia. Se vocês quiserem saber mais sobre as diferenças das funções LEN() e da DATALENGTH(), dêem uma lida neste post aqui. Ele é em inglês, mas é muito explicativo e completo.
Abraços!
Como identificar as ocorrências de um caractere específico numa string ou tabela count how many character characters string row
Como identificar as ocorrências de um caractere específico numa string ou tabela count how many character characters string row
