Introdução
Fala pessoal!
Nesse artigo eu gostaria de compartilhar com vocês um pequeno código que eu precisei utilizar hoje para fazer um UPDATE numa tabela relativamente grande (55M+ de registros) numa base Azure SQL Database e, depois de 1h e 30 mins esperando, deu erro de conexão e tive que fazer tudo novamente.
Não apenas nesse caso, mas pode acontecer de estourar o log e dar erro na operação também, e, como sabemos, quando ocorre um erro durante UPDATE ou DELETE, o rollback automático é iniciado e nenhuma linha é alterada de fato. Quebrando essa operação única em operações menores e segmentadas vai permitir que o log seja liberado e assim, minimize possíveis estouros de log.
Você também pode querer quebrar essas operações grandes e demoradas em pequenas partes para conseguir acompanhar o progresso ou a sua janela de manutenção não é suficiente para processar o UPDATE/DELETE em todas as linhas necessárias e você quer continuar em outra janela.
Já vi casos também de tabelas com triggers e que podem acabar gerando um overhead muito grande ao executar um UPDATE/DELETE que altere muitas linhas. E temos que lembrar também de locks na tabela, que ao quebrar em partes menores, podem ser liberados rapidamente enquanto o próximo lote está iniciando o processamento.
São vários os motivos que podem influenciar na decisão de participar um UPDATE/DELETE grande e nesse artigo vou mostrar algumas formas fáceis de fazer isso.
Como apagar ou atualizar dados em tabelas grandes
UPDATE particionado por campo inteiroUPDATE particionado por campo inteiro
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
DECLARE @Min INT, @Max INT, @Contador INT = 0, @Aumento INT = 1000000, @LimiteInferior INT = 0, @LimiteSuperior INT = 0, @Msg VARCHAR(MAX) SELECT @Min = MIN(Id_Registro), @Max = MAX(Id_Registro) FROM dbo.Tabela WHILE(@LimiteSuperior < @Max) BEGIN SET @LimiteInferior = @Min + (@Contador * @Aumento) SET @LimiteSuperior = @LimiteInferior + @Aumento UPDATE A SET Dt_Registro = (CASE WHEN ISNUMERIC(A.Data_Registro_String) = 1 THEN CONVERT(DATE, DATEADD(DAY, TRY_CONVERT(INT, A.Data_Registro_String), '1900-01-01')) WHEN LEN(A.Data_Registro_String) = 10 AND TRY_CONVERT(DATE, A.Data_Registro_String, 103) IS NOT NULL THEN CONVERT(DATE, A.Data_Registro_String, 103) ELSE CONVERT(DATE, A.Data_Registro_String) END) FROM dbo.Tabela A WHERE Id_Registro >= @LimiteInferior AND Id_Registro < @LimiteSuperior SET @Contador += 1 SET @Msg = CONCAT('Processando dados no intervalo ', @LimiteInferior, '-', @LimiteSuperior, '...') RAISERROR(@Msg, 1, 1) WITH NOWAIT END |
Resultado:
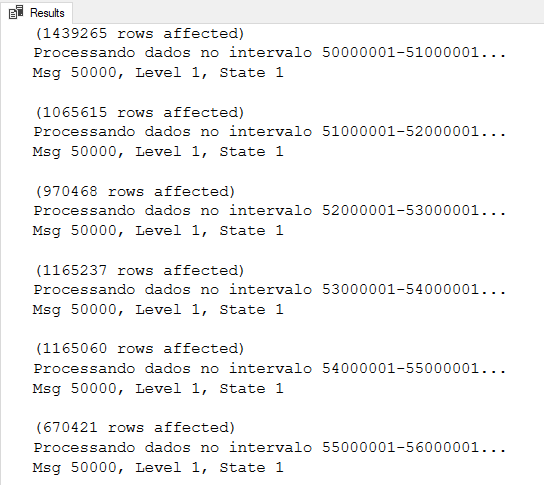
UPDATE particionado por campo data
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
DECLARE @Min DATE, @Max DATE, @Contador INT = 0, @Aumento INT = 30, @LimiteInferior DATE = '1900-01-01', @LimiteSuperior DATE = '1900-01-01', @Msg VARCHAR(MAX) SELECT @Min = MIN(Dt_Cadastro), @Max = MAX(Dt_Cadastro) FROM dbo.Tabela WHILE(@LimiteSuperior < @Max) BEGIN SET @LimiteInferior = DATEADD(DAY, (@Contador * @Aumento), @Min) SET @LimiteSuperior = DATEADD(DAY, @Aumento, @LimiteInferior) UPDATE A SET Dt_Registro = (CASE WHEN ISNUMERIC(A.Data_Registro_String) = 1 THEN CONVERT(DATE, DATEADD(DAY, TRY_CONVERT(INT, A.Data_Registro_String), '1900-01-01')) WHEN LEN(A.Data_Registro_String) = 10 AND TRY_CONVERT(DATE, A.Data_Registro_String, 103) IS NOT NULL THEN CONVERT(DATE, A.Data_Registro_String, 103) ELSE CONVERT(DATE, A.Data_Registro_String) END) FROM dbo.Tabela A WHERE Dt_Cadastro >= @LimiteInferior AND Dt_Cadastro < @LimiteSuperior SET @Contador += 1 SET @Msg = CONCAT('Processando dados no intervalo ', CONVERT(VARCHAR(10), @LimiteInferior, 103), '-', CONVERT(VARCHAR(10), @LimiteSuperior, 103), '...') RAISERROR(@Msg, 1, 1) WITH NOWAIT END |
Resultado:
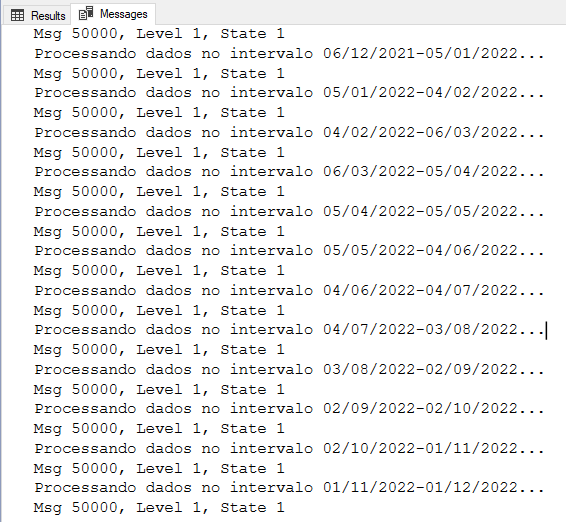
DELETE TOP(N) particionado usando porcentagem
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
DECLARE @Msg VARCHAR(MAX), @Qt_Linhas INT WHILE (1=1) BEGIN DELETE TOP(10) PERCENT FROM dbo.Tabela WHERE [Status] = 6 SET @Qt_Linhas = @@ROWCOUNT IF (@Qt_Linhas = 0) BREAK SET @Msg = CONCAT('Quantidade de Linhas Apagadas: ', @Qt_Linhas) RAISERROR(@Msg, 1, 1) WITH NOWAIT END |
Resultado:

Observação: Essa solução pode apresentar problemas em tabelas muito grandes, pois 10% pode representar um volume muito grande de linhas. E quando poucos registros vão restando, os 10% podem exigir muitas iterações para serem apagados.

DELETE TOP(N) particionado usando quantidade de linhas
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
DECLARE @Msg VARCHAR(MAX), @Qt_Linhas INT WHILE (1=1) BEGIN DELETE TOP(100000) FROM dbo.Tabela WHERE [Status] = 6 SET @Qt_Linhas = @@ROWCOUNT IF (@Qt_Linhas = 0) BREAK SET @Msg = CONCAT('Quantidade de Linhas Apagadas: ', @Qt_Linhas) RAISERROR(@Msg, 1, 1) WITH NOWAIT END |
Resultado:

E é isso aí, pessoal!
Espero que tenham gostado e um grande abraço!

Boas dicas. Mas no caso do delete eu sempre uso o TRUNCATE TABLE. Já que vai deletar tudo mesmo! Inclsuive a perfomance é bem maior, utiliza menos recurso de log, não aciona trigger e ainda limpa todas as páginas da tabela.
Oi Colli, boa ideia, mas a minha ideia no post é pra expurgo de dados, onde não seriam todos os dados apagados, aí no truncate não iria funcionar.
Boas dicas. Mas no caso do delete para não perder tempo fazendo count, eu gosto de no while passar 1=2, e após o delete passar
if @@rowcount = 0 break
Os primeiros counts podem demorar muito caso a tabela seja muito grande, ou se tiver uma cláusula where para apagar apenas parte da tabela.
Boa ideia! Realmente fica mais rápido mesmo.