Olá pessoal!
Neste post, gostaria de demonstrar a vocês como utilizar o comando MERGE, disponível desde o SQL Server 2008, para realizar comandos de INSERT e UPDATE entre duas tabelas em uma única instrução.
Para os exemplos desse post, vou utilizar uma base que vou criar utilizando o script abaixo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
IF (OBJECT_ID('dbo.Venda') IS NOT NULL) DROP TABLE dbo.Venda CREATE TABLE dbo.Venda ( Id_Venda INT IDENTITY(1,1) NOT NULL, Dt_Venda DATE NOT NULL, Id_Produto INT NOT NULL, Quantidade INT NOT NULL, Valor NUMERIC(9, 2) NOT NULL ) INSERT INTO dbo.Venda ( Dt_Venda, Id_Produto, Quantidade, Valor ) VALUES ( '2018-09-21', 1, 2, 25.99 ), ( '2018-09-21', 2, 3, 29.99 ), ( '2018-09-21', 1, 1, 15.99 ), ( '2018-09-22', 1, 2, 25.99 ), ( '2018-09-22', 2, 1, 10.00 ), ( '2018-09-22', 9, 1, 35.99 ), ( '2018-09-22', 5, 3, 20.00 ), ( '2018-09-22', 3, 2, 25.87 ), ( '2018-09-22', 2, 1, 11.25 ), ( '2018-09-22', 1, 1, 21.90 ), ( '2018-09-22', 4, 3, 29.99 ) IF (OBJECT_ID('dbo.Dim_Venda') IS NOT NULL) DROP TABLE dbo.Dim_Venda CREATE TABLE dbo.Dim_Venda ( Id_Venda INT NOT NULL, Dt_Venda DATE NOT NULL, Id_Produto INT NOT NULL, Quantidade INT NOT NULL, Valor NUMERIC(9, 2) NOT NULL ) INSERT INTO dbo.Dim_Venda ( Id_Venda, Dt_Venda, Id_Produto, Quantidade, Valor ) SELECT Id_Venda, Dt_Venda, Id_Produto, Quantidade, Valor FROM dbo.Venda WHERE Dt_Venda = '2018-09-21' |
E as nossas tabelas de origem e destino ficam assim:
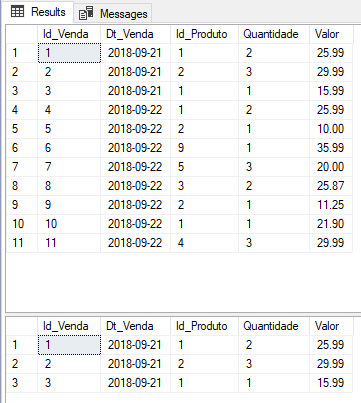
Introdução
Atividade muito comum no dia a dia de profissionais que trabalham com dados, especialmente quem trabalha com ETL, a tarefa de atualizar uma tabela baseado nos dados de uma outra tabela, costuma acabar gerando 2 operações distintas para a atualização dos dados:
Método 1: Insert/Update
- Atividade 1: Atualizar os registros que existem nas duas tabelas
- Atividade 2: Inserir os registros que só existem na tabela de origem
Vamos ver como faríamos isso:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
-- Atividade 1: Atualizar os registros que existem nas duas tabelas UPDATE A SET A.Dt_Venda = B.Dt_Venda, A.Id_Produto = B.Id_Produto, A.Quantidade = B.Quantidade, A.Valor = B.Valor FROM dbo.Dim_Venda A JOIN dbo.Venda B ON A.Id_Produto = B.Id_Venda -- Atividade 2: Inserir os registros que só existem na tabela de origem INSERT INTO dbo.Dim_Venda ( Id_Venda, Dt_Venda, Id_Produto, Quantidade, Valor ) SELECT A.Id_Venda, A.Dt_Venda, A.Id_Produto, A.Quantidade, A.Valor FROM dbo.Venda A LEFT JOIN dbo.Dim_Venda B ON A.Id_Venda = B.Id_Venda WHERE B.Id_Venda IS NULL SELECT * FROM dbo.Dim_Venda SELECT * FROM dbo.Venda |
E como ficaram os dados da tabela?
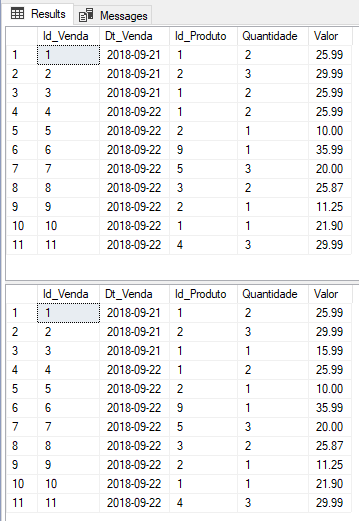
Método 2: Delete/Insert
- Atividade 1: Apaga os registros que existem nas duas tabelas
- Atividade 2: Inserir os registros que da tabela de origem
A qual podemos entender como ela funciona através do script abaixo:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
-- Atividade 1: Apaga os registros que existem nas duas tabelas DELETE A FROM dbo.Dim_Venda A JOIN dbo.Venda B ON A.Id_Produto = B.Id_Venda -- Atividade 2: Inserir os registros que só existem na tabela de origem INSERT INTO dbo.Dim_Venda ( Id_Venda, Dt_Venda, Id_Produto, Quantidade, Valor ) SELECT A.Id_Venda, A.Dt_Venda, A.Id_Produto, A.Quantidade, A.Valor FROM dbo.Venda A LEFT JOIN dbo.Dim_Venda B ON A.Id_Venda = B.Id_Venda WHERE B.Id_Venda IS NULL SELECT * FROM dbo.Dim_Venda SELECT * FROM dbo.Venda |
Resultado:
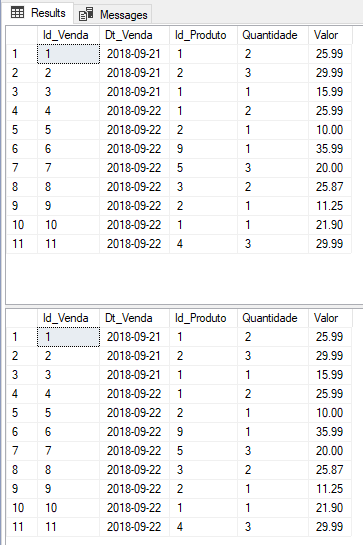
Utilizando o comando MERGE para INSERT + UPDATE + DELETE
Até agora, não apresentei nenhuma novidade, né? Comandos de DELETE/INSERT e UPDATE/INSERT são bem comuns no dia a dia de profissionais da área de dados.
Entretanto, para resolver esse problema, a partir do SQL Server 2008 podemos utilizar o comando MERGE, que nos permite realizar essa mesma atividade em apenas 1 instrução. Seu funcionamento é simples: Uma ou mais colunas das tabelas envolvidas são consideradas chaves (identificadores) para caso o valor da chave exista na tabela destino, os valores serão atualizados de acordo com a tabela origem. Caso esse identificador não exista, esse registro será inserido na tabela destino.
Sua sintaxe funciona assim:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
MERGE dbo.Dim_Venda AS Destino USING dbo.Venda AS Origem ON (Origem.Id_Venda = Destino.Id_Venda) -- Registro existe nas 2 tabelas WHEN MATCHED THEN UPDATE SET Destino.Dt_Venda = Origem.Dt_Venda, Destino.Id_Produto = Origem.Id_Produto, Destino.Quantidade = Origem.Quantidade, Destino.Valor = Origem.Valor -- Registro não existe no destino. Vamos inserir. WHEN NOT MATCHED THEN INSERT VALUES(Origem.Id_Venda, Origem.Dt_Venda, Origem.Id_Produto, Origem.Quantidade, Origem.Valor); |
Resultado:
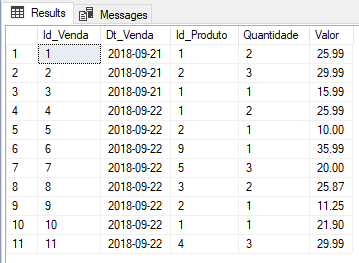
Controlando a cláusula NOT MATCHED na Origem e Destino
Podemos também, controlar quando um registro não existe no destino ou na origem, e tomar decisões diferentes para essas 2 situações:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
MERGE dbo.Dim_Venda AS Destino USING dbo.Venda AS Origem ON (Origem.Id_Venda = Destino.Id_Venda) -- Registro existe nas 2 tabelas WHEN MATCHED THEN UPDATE SET Destino.Dt_Venda = Origem.Dt_Venda, Destino.Id_Produto = Origem.Id_Produto, Destino.Quantidade = Origem.Quantidade, Destino.Valor = Origem.Valor -- Registro não existe na origem, apenas no destino. Vamos apagar o dado da origem. WHEN NOT MATCHED BY SOURCE THEN DELETE -- Registro não existe no destino. Vamos inserir. WHEN NOT MATCHED BY TARGET THEN INSERT VALUES(Origem.Id_Venda, Origem.Dt_Venda, Origem.Id_Produto, Origem.Quantidade, Origem.Valor); |
Atualizando valores específicos, através de filtros específicos
Pode ser necessário atualizar apenas a quantidade e valor, e nos casos em que estes forem diferentes:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
MERGE dbo.Dim_Venda AS Destino USING dbo.Venda AS Origem ON (Origem.Id_Venda = Destino.Id_Venda) -- Registro existe nas 2 tabelas WHEN MATCHED AND (Origem.Quantidade <> Destino.Quantidade OR Origem.Valor <> Destino.Valor) THEN UPDATE SET Destino.Quantidade = Origem.Quantidade, Destino.Valor = Origem.Valor -- Registro não existe no destino. Vamos inserir. WHEN NOT MATCHED THEN INSERT VALUES(Origem.Id_Venda, Origem.Dt_Venda, Origem.Id_Produto, Origem.Quantidade, Origem.Valor); |
Exibindo uma saída com todas as alterações realizadas pelo MERGE
E se quisermos coletar os resultados do MERGE e exibir as operações realizadas na tela ? Basta usar o OUTPUT!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
MERGE dbo.Dim_Venda AS Destino USING dbo.Venda AS Origem ON (Origem.Id_Venda = Destino.Id_Venda) -- Registro existe nas 2 tabelas WHEN MATCHED THEN UPDATE SET Destino.Dt_Venda = Origem.Dt_Venda, Destino.Id_Produto = Origem.Id_Produto, Destino.Quantidade = Origem.Quantidade, Destino.Valor = Origem.Valor -- Registro não existe na origem, apenas no destino. Vamos apagar o dado da origem. WHEN NOT MATCHED BY SOURCE THEN DELETE -- Registro não existe no destino. Vamos inserir. WHEN NOT MATCHED BY TARGET THEN INSERT VALUES(Origem.Id_Venda, Origem.Dt_Venda, Origem.Id_Produto, Origem.Quantidade, Origem.Valor) OUTPUT $action, Deleted.Id_Venda, Deleted.Dt_Venda, Deleted.Id_Produto, Deleted.Quantidade, Deleted.Valor, Inserted.Id_Venda, Inserted.Dt_Venda, Inserted.Id_Produto, Inserted.Quantidade, Inserted.Valor; |
Resultado:

Armazenando a saída do MERGE em uma tabela
Gostaria de salvar os registros de log em uma tabela para consultar os dados ?
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
CREATE TABLE dbo.Dim_Venda_Log ( [Id_Log] BIGINT IDENTITY(1,1) NOT NULL PRIMARY KEY CLUSTERED, [Acao] NVARCHAR(10), [Inserted_Id_Venda] INT, [Inserted_Dt_Venda] DATE, [Inserted_Id_Produto] INT, [Inserted_Quantidade] INT, [Inserted_Valor] DECIMAL(9, 2), [Deleted_Id_Venda] INT, [Deleted_Dt_Venda] DATE, [Deleted_Id_Produto] INT, [Deleted_Quantidade] INT, [Deleted_Valor] DECIMAL(9, 2) ) WITH(DATA_COMPRESSION=PAGE) MERGE dbo.Dim_Venda AS Destino USING dbo.Venda AS Origem ON (Origem.Id_Venda = Destino.Id_Venda) -- Registro existe nas 2 tabelas WHEN MATCHED THEN UPDATE SET Destino.Dt_Venda = Origem.Dt_Venda, Destino.Id_Produto = Origem.Id_Produto, Destino.Quantidade = Origem.Quantidade, Destino.Valor = Origem.Valor -- Registro não existe na origem, apenas no destino. Vamos apagar o dado da origem. WHEN NOT MATCHED BY SOURCE THEN DELETE -- Registro não existe no destino. Vamos inserir. WHEN NOT MATCHED BY TARGET THEN INSERT VALUES(Origem.Id_Venda, Origem.Dt_Venda, Origem.Id_Produto, Origem.Quantidade, Origem.Valor) OUTPUT $action, Inserted.*, Deleted.* INTO dbo.Dim_Venda_Log; SELECT * FROM dbo.Dim_Venda_Log |
Utilizando consultas como dados de origem
O MERGE também nos permite juntar dados vindos de consultas ao invés de tabelas fixas, e utilizar JOINS, caso necessário.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
MERGE dbo.Dim_Venda AS Destino USING (SELECT Id_Venda, Dt_Venda, Id_Produto, Quantidade, Valor FROM dbo.Venda WHERE Dt_Venda = '2018-09-22') AS Origem ON (Origem.Id_Venda = Destino.Id_Venda) -- Registro existe nas 2 tabelas WHEN MATCHED THEN UPDATE SET Destino.Dt_Venda = Origem.Dt_Venda, Destino.Id_Produto = Origem.Id_Produto, Destino.Quantidade = Origem.Quantidade, Destino.Valor = Origem.Valor -- Registro não existe na origem, apenas no destino. Vamos apagar o dado da origem. WHEN NOT MATCHED BY SOURCE THEN DELETE -- Registro não existe no destino. Vamos inserir. WHEN NOT MATCHED BY TARGET THEN INSERT VALUES(Origem.Id_Venda, Origem.Dt_Venda, Origem.Id_Produto, Origem.Quantidade, Origem.Valor) OUTPUT $action, Inserted.*, Deleted.*; |
Resultado – vejam que, como trouxe apenas os dados do dia 22/09 no MERGE, os dados do dia 21/09 que foram carregados manualmente antes do MERGE foram apagados da tabela de destino, pois não existiam na origem
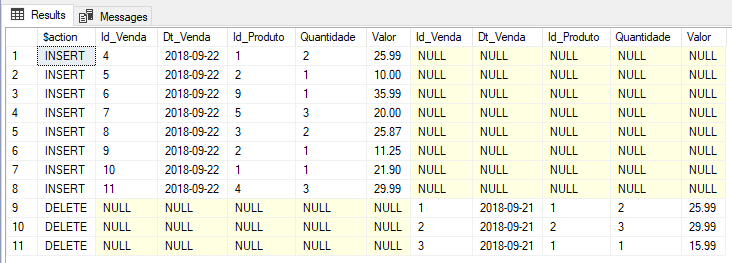
Utilizando CTE com JOIN para gerar dados da origem
O Merge também permite utilizar CTE para geração do resultset de origem dos dados e utilizar JOINS, caso necessário.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
;WITH cteVenda AS ( SELECT A.Id_Venda, A.Dt_Venda, A.Id_Produto, A.Quantidade, A.Valor, B.Id_Erro, B.Dt_Erro, B.Ds_Erro FROM dbo.Venda A LEFT JOIN Consultoria.dbo.Log_Erro B ON A.Id_Produto = B.Id_Erro WHERE A.Dt_Venda = '2018-09-21' ) MERGE dbo.Dim_Venda AS Destino USING cteVenda AS Origem ON (Origem.Id_Venda = Destino.Id_Venda) -- Registro existe nas 2 tabelas WHEN MATCHED THEN UPDATE SET Destino.Dt_Venda = Origem.Dt_Venda, Destino.Id_Produto = Origem.Id_Produto, Destino.Quantidade = Origem.Quantidade, Destino.Valor = Origem.Valor -- Registro não existe na origem, apenas no destino. Vamos apagar o dado da origem. WHEN NOT MATCHED BY SOURCE THEN DELETE -- Registro não existe no destino. Vamos inserir. WHEN NOT MATCHED BY TARGET THEN INSERT VALUES(Origem.Id_Venda, Origem.Dt_Venda, Origem.Id_Produto, Origem.Quantidade, Origem.Valor) OUTPUT $action, Inserted.*, Deleted.*; |
Resultado:

Cuidados ao utilizar o MERGE
Agora que demonstrei várias formas de utilizar o MERGE no SQL Server, gostaria de alertá-los sobre a existência de alguns bugs ao utilizar o MERGE no SQL Server 2008, que vão desde a saídas incorretas ao utilizar o OUTPUT a erros severos como o demonstrado abaixo:
Msg 0, Level 11, State 0, Line 0
A severe error occurred on the current command. The results, if any, should be discarded.
Msg 0, Level 20, State 0, Line 0
A severe error occurred on the current command. The results, if any, should be discarded.
Se você está utilizando a versão 2008 (AINDA), atualize o seu SQL com a última versão do SP e Cumulative Update disponível e leia com atenção aos artigos que vou disponibilizar abaixo, pois eles tem vários cenários que podem gerar dor de cabeça ao utilizar o MERGE no SQL Server 2008 (nas versões 2012+ esses bugs não existem mais):
- http://sqlblog.com/blogs/paul_white/archive/2010/08/04/another-interesting-merge-bug.aspx
- http://andreyzavadskiy.com/2015/07/23/sql-server-2008r2-causes-severe-error-in-merge-output/
- https://www.mssqltips.com/sqlservertip/3074/use-caution-with-sql-servers-merge-statement/
Utilizando a Stored Procedure stpETL_Upsert
Para facilitar o uso de MERGE, especialmente em tabelas com muitas colunas, vou compartilhar com vocês a Stored Procedure stpETL_Upsert, criada originalmente pelo Murilo Mielke e adaptada por mim, que tem como objetivo, facilitar o uso de MERGE em situações do cotidiano.
Parâmetros da SP:
- @Nm_Source: Parâmetro do tipo VARCHAR(MAX), ele contém o nome da tabela de origem dos dados (source). O nome da tabela deve ser especifico na forma completa (database.schema.tabela)
- @Nm_Target: Parâmetro do tipo VARCHAR(MAX), ele contém o nome da tabela de destino dos dados (target), ou seja, onde os dados serão inseridos/atualizados. O nome da tabela deve ser especifico na forma completa (database.schema.tabela)
- @Cd_Join: Parâmetro do tipo VARCHAR(MAX), deve ser informado a coluna ou as colunas do JOIN para ligar os dados da tabela origem (source) e destino (target). Para o uso simplificado, você pode especificar apenas os nomes das colunas, caso seja o mesmo entre a origem e o destino, separando por vírgula “,” caso haja mais de uma coluna para realizar o JOIN. Caso o nome das colunas entre origem e destino sejam diferentes, deve-se utilizar o formato nome_coluna_origem:nome_coluna_destino, utilizando também o separador vírgula “,” em caso de múltiplas colunas
- @Cd_Chave: Parâmetro do tipo VARCHAR(MAX), deve ser informado o nome da coluna sequencial (IDENTITY) da tabela destino, para evitar que o SP tente realizar um UPDATE ou INSERT utilizando essa coluna. Caso não tenha coluna IDENTITY no destino (target), pode-se ignorar esse parâmetro, uma vez que seu valor padrão já é vazio.
- @Fl_Update: Parâmetro do tipo BIT, com valor padrão = 1, essa coluna informa à SP se os registros na tabela de destino (target) devem ser atualizados caso existam na origem e no destino (@Fl_Update = 1) ou não.
- @Fl_Debug: Parâmetro do tipo BIT que faz com que a SP mostre na janela de saída o comando MERGE gerado ao final da execução do mesmo
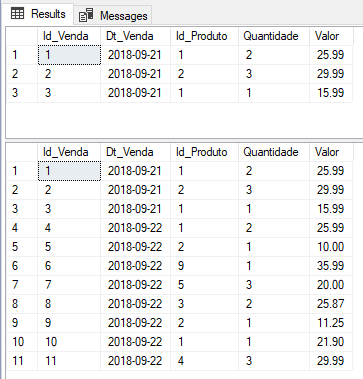
Exemplo 1 – Uso simples
Utilizando o mesmo cenário dos exemplos desse artigo, vamos utilizar a stpETL_Upset para realizar nosso MERGE:
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT * FROM dbo.Dim_Venda EXEC dbo.stpETL_Upsert @Nm_Source = 'dirceuresende.dbo.Venda', -- varchar(max) @Nm_Target = 'dirceuresende.dbo.Dim_Venda', -- varchar(max) @Cd_Join = 'Id_Venda', -- varchar(max) @Cd_Chave = '', -- varchar(max) @Fl_Update = 1, -- bit @Fl_Debug = 1 -- bit SELECT * FROM dbo.Dim_Venda |
Resultado:
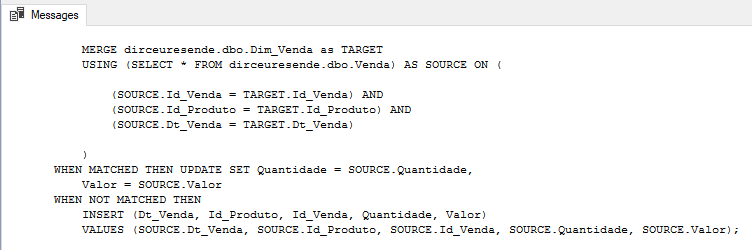
Código do MERGE gerado:

Exemplo 2 – Utilizando várias colunas para o JOIN
Caso você precise utilizar várias colunas para realizar o JOIN dos dados, basta separá-los por vírgula “,” na chamada da SP:
|
1 2 3 4 5 6 7 |
EXEC dbo.stpETL_Upsert @Nm_Source = 'dirceuresende.dbo.Venda', -- varchar(max) @Nm_Target = 'dirceuresende.dbo.Dim_Venda', -- varchar(max) @Cd_Join = 'Id_Venda, Id_Produto, Dt_Venda', -- varchar(max) @Cd_Chave = '', -- varchar(max) @Fl_Update = 1, -- bit @Fl_Debug = 1 -- bit |
Código gerado:
Exemplo 3 – Utilizando JOINS com colunas diferentes
Caso as colunas do JOIN não tenham exatamente o mesmo nome ou você queira utilizar mais de uma cláusula do JOIN, você pode utilizar a SP conforme demonstrado abaixo, utilizando a sintaxe nome_coluna_tabela_origem:nome_coluna_tabela_destino, podendo ainda, utilizar o caractere vírgula “,” para utilizar vários mapeamentos.
No exemplo abaixo, a tabela de origem “Venda” possui um campo chamado Id_Venda, que vai realizar o JOIN com a coluna Cod_Venda na tabela de destino “Dim_Venda”.
|
1 2 3 4 5 6 7 |
EXEC dbo.stpETL_Upsert @Nm_Source = 'dirceuresende.dbo.Venda', -- varchar(max) @Nm_Target = 'dirceuresende.dbo.Dim_Venda', -- varchar(max) @Cd_Join = 'Id_Venda:Cod_Venda', -- varchar(max) @Cd_Chave = '', -- varchar(max) @Fl_Update = 1, -- bit @Fl_Debug = 1 -- bit |
Código gerado:

Código-fonte
Gostou da stpETL_Upset? Bem prática né? Vou disponibilizar o código-fonte dessa Stored Procedure aqui embaixo para que vocês possam começar a utilizá-la no seu dia a dia. Não se esqueçam de criar os objetos fncSplit e fncSplitTexto que estão nos requisitos hein, senão vai dar erro e vocês vão reclamar comigo nos comentários.. kkkkk
Visualizar código-fonte da stpETL_Upsert
Requisitos:
Referências
- https://docs.microsoft.com/pt-br/sql/t-sql/statements/merge-transact-sql?view=sql-server-2017
- https://www.mssqltips.com/sqlservertip/1704/using-merge-in-sql-server-to-insert-update-and-delete-at-the-same-time/
Bom, pessoal!
Espero que tenham gostado desse post e até a próxima.
Grande abraço!


Dirceu, Boa tarde. seria uma bo pratiica ultilizar o Merge para fazer ETL para construção de um dw?
Muito bom, Dirceu! Mostrou algumas situações de uso que não são muito abordadas e me ajudou bastante!..
Excelente post. Uso o merge em poucas situações, mas é sempre bem prático.
Excelente post Dirceu, recentemente estávamos com um desafio de usar o merge num job afim de fazer carga do tipo SCD 2 sem ferramenta etl, ele atendeu magnificamente. Essa procedure do Murilo é show!! Abs