Durante este post, irei demonstrar como criar e restaurar backups no Oracle Database utilizando as ferramentas exp e imp, e que permitem gerar backups completos de um owner e restaurar em outro servidor.
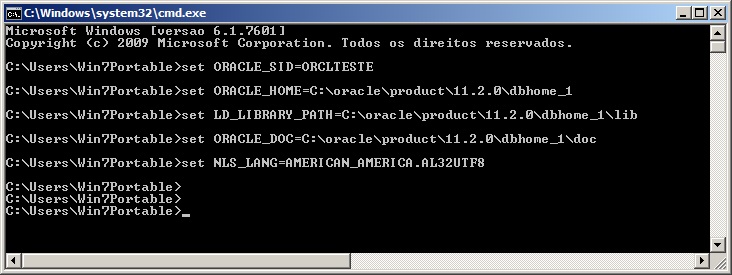
Definição das variáveis de ambiente no Windows
|
1 2 3 |
SET ORACLE_SID=ORCLTESTE SET ORACLE_HOME=C:\oracle\product\11.2.0\dbhome_1 SET NLS_LANG=AMERICAN_AMERICA.AL32UTF8 |
Definição das variáveis de ambiente no Linux
|
1 2 3 |
EXPORT ORACLE_SID=ORCLTESTE EXPORT ORACLE_HOME=/oracle/product/11.1.0/db_1/ EXPORT NLS_LANG=AMERICAN_AMERICA.AL32UTF8 |
Parâmetros do Export
Vou demonstrar aqui como exportar os dados do banco para um arquivo de dump, que poderá ser utilizado para restaurar os dados dados e replicar o banco em outra instância/servidor.
Seguem alguns parâmetros:
- file = arquivo.dmp: Define o nome de arquivo de dump que será gerado. Caso não seja informado, o nome do arquivo será “EXPDAT.DMP”
- log = arquivo.log: Define o nome de arquivo de log que será gerado. Caso não seja informado, não será gerado log.
- owner = <owner1>,<owner2>: Define o nome do(s) owner(s) que será(ão) exportado(s)
- full = y: Indica se deverá ser exportado todo o banco de dados, com usuários, tablespaces, grants, etc.
- grants = y: Define se os privilégios concedidos pelo owner serão exportados
- indexes = y: Define se os objetos de índice serão exportados
- compress = y: Define se o arquivo de dump será compactado para reduzir o tamanho do arquivo final
- consistent = y: Define se o Oracle irá evitar que os dados alterado durante o export sejam exportados no arquivo de dump. Essa operação irá utilizar a área de undo para isso armazenar essas alterações e aplicá-las no banco após o export.
- constraints = y: Define se as contraints de PK e FK serão exportadas no arquivo de dump.
- direct = y: Define se os dados exportados irão pular a camada de parse do Oracle (SQL command-processing layer – evaluating buffer), que valida a sintaxe dos comandos e faz o export ser mais rápido (cerca de 10% geralmente)
- feedback = 0: Define a cada quantos registros o utilitário exp irá exibir o progresso na tela. 0 é desativado.
- filesize = 10MB: Define o limite de tamanho por arquivo. Caso seja especificado 2 MB, por exemplo, o exp irá quebrar o arquivo de dump em arquivos de 2 MB, que precisam ser informados no parâmetro FILE. Caso não seja informado, o arquivo de dump será composto por apenas 1 arquivo.
- flashback_scn: Permite gerar o export com os dados através do SCN, onde você obtém o valor atual do database e garante que os dados não serão alterados após o export. Para descobrir o valor atual do SCN, basta executar a query
select current_scn from v$database; - flashback_time: Permite gerar o export com dados de uma data específica.
- tables = regions: Permite definir as tabelas que serão exportadas
- query = “condicao”: Permite definir uma condição para exportar os dados. O parâmetro TABLES deve ser informado e a condição deve ser aplicável para todas essas tabelas.
- parfile = “caminho do arquivo”: Permite definir um arquivo de parâmetros para o export, onde cada parâmetro deverá ficar em uma linha e o utilitário irá ler esse arquivo e executar o comando exp utilizando esses parâmetros.
Exemplo de parfile:
userid=usuario/senha
file=exp_HR_20150319.dmp
log=exp_HR_20150319.log
owner=hr
full=n
buffer=409600000
rows=n
statistics=none
direct=y
consistent=y
- statistics = none: Permite definir se as estatísticas geradas pelo banco para performance devem ser exportadas ou não. As opções são none, compute e estimate.
- triggers = y: Define se as triggers das tabelas deverão ser exportadas
- tablespaces = tablespace1,tablespace2: Caso seja informado, esse parâmetro faz com que o exp gere os dados de todas as tabelas que estão alocadas nas tablespaces informadas
- buffer = 4096: Define o tamanho (em bytes) do buffer utilizado pelo export para fazer o fetch das linhas (Só se aplica quando direct=n)
- help = y: Informações de ajuda e documentação
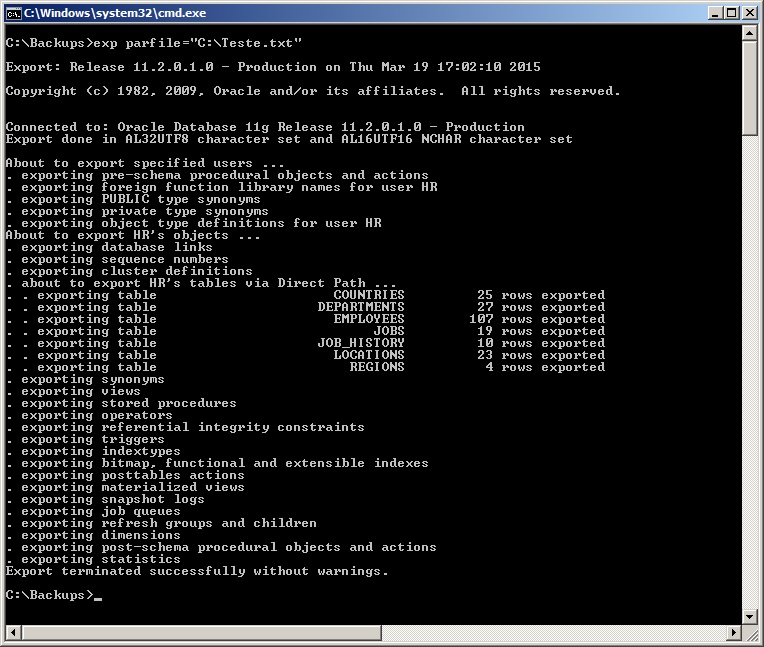
Exportando os dados – Gerando o arquivo de backup
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# Gerando backup de um owner, sem dados, apenas tabelas (rows=n) exp usuario/senha file=exp_HR_20150319.dmp log=exp_HR_20150319.log owner=hr buffer=409600000 rows=n # Gerando backup dos owners HR e SYS, com dados (rows=y) exp usuario/senha file=exp_HR_20150319.dmp owner=hr,sys full=n rows=y statistics=none direct=y consistent=y # Gerando backup de todos os objetos de todos os owners da instância (full=y) exp usuario/senha file=exp_HR_20150319.dmp full=y rows=y statistics=none direct=y consistent=y # Gerando backup de todos os objetos de um owner, em 3 arquivos de no máximo 10 MB exp usuario/senha file=exp_HR_20150319_1.dmp,HR_20150319_2.dmp,HR_20150319_3.dmp filesize=10MB # Gerando backup dos dados a partir de uma query exp usuario/senha file=exp_HR_20150319.dmp tables=hr.jobs query=\"where max_salary <= 10000\" # Gerando backup dos dados usando um arquivo de configuração (PARFILE) exp parfile="C:\parfile.dat" # Como eu costumo utilizar - Crio um arquivo parfile.dat com o userid exp parfile="C:\parfile.dat" file=exp_<owner>_<instancia>.dmp log=exp_<owner>_<instancia>.log buffer=409600000 statistics=none direct=y consistent=y |
Parâmetros do Import
Vou demonstrar aqui como importar os dados do banco a partir de um arquivo de dump.
Seguem alguns parâmetros, além dos demonstrados acima para o export, que também são aplicáveis no import:
- commit = n: Caso commit=y, o imp irá realizar um commit após cada bloco de inserção de dados. Caso contrário, o commit será realizado a cada tabela importada
- compile = y: Define se o imp irá compilar as procedure, functions e triggers após a criação das mesmas.
- fromuser = usuario: Identifica o(s) owner(s) de origem dos dados que foram exportados
- touser = usuario: Identifica o(s) owner(s) de destino onde os dados que serão importados. Os owners devem existir na instância de destino antes de executar o import
- full = y: Importa todo o arquivo de dump, sem filtros de objetos
- ignore = y: Define se o imp irá ignorar erros na criação de objetos ou parar a abortar a operação em caso de erro
- show = y: Define se o imp irá apenas listar o conteúdo do dump ao invés de importá-lo
- statistics = valor: Define a forma que o imp irá importar as estatísticas coletadas do banco no Export. As opções possíveis são: Always (Sempre importa a estatísticas), None (Não importa e nem recalcula as estatísticas), Safe (Importa as estatísticas se elas não forem questionáveis. Caso contrário, recalcula) ou Recalculate (Não importa as estatísticas, mas as recalcula)
Importando os dados para novo owner – Preparação do ambiente
Antes de realizar o import, precisaremos criar o usuários e as tablespaces utilizadas por esse usuário na instância de destino.
Note que o tamanho das tablespaces e datafiles deve ser calculado de forma que haja espaço suficiente para receber os dados de origem. Você pode obter esses dados replicando os mesmos valores das tablespaces de origem ou ativando a opção autoextend do datafile, que faz com que ele aumente de tamanho à medida que for necessário. Além disso, defini a quota do usuário na tablespace criada como ilimitada, de modo que ele consiga alocar toda a tablespace, se necessário.
Essa não é uma boa prática, pois você como DBA, deve avaliar a alocação de espaço no processo de export/import, mas para testes é o ideal.
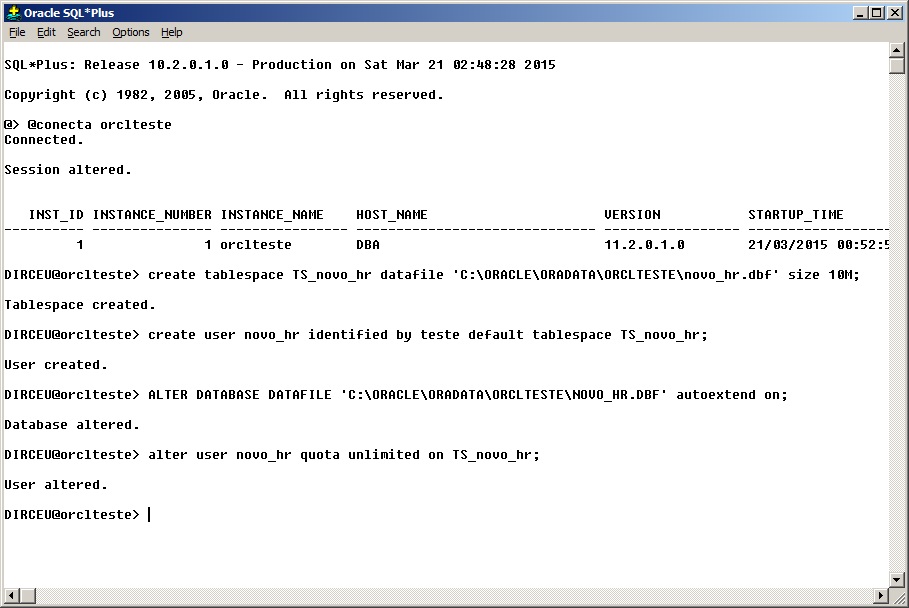
Comandos utilizados:
|
1 2 3 4 |
create tablespace TS_novo_hr datafile 'C:\ORACLE\ORADATA\ORCLTESTE\novo_hr.dbf' size 10M; create user novo_hr identified by teste default tablespace TS_novo_hr; ALTER DATABASE DATAFILE 'C:\ORACLE\ORADATA\ORCLTESTE\NOVO_HR.DBF' autoextend on; alter user novo_hr quota unlimited on TS_novo_hr; |
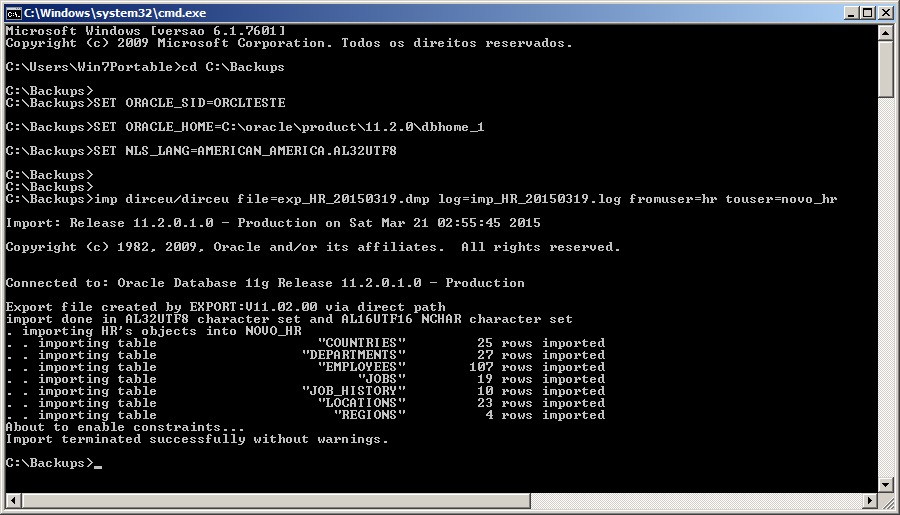
Importando os dados para novo owner
|
1 2 3 4 5 6 7 8 |
# Exemplo simples, importando do owner HR para NOVO_HR e gerando arquivo de log imp dirceu/dirceu file=exp_HR_20150319.dmp log=imp_HR_20150319.log fromuser=hr touser=novo_hr # Realizando o import sem trazer estruturas adicionais imp dirceu/dirceu file=exp_HR_20150319.dmp log=imp_HR_20150319.log fromuser=hr touser=novo_hr grants=n commit=n ignore=y analyze=n constraints=n indexes=n # Como eu costumo utilizar - Crio um arquivo parfile.dat com o userid imp parfile="C:\parfile.dat" file=exp_<owner>_<instancia>.dmp buffer=409600000 log=imp_<owner>_<instancia>.dmp fromuser=<owner> touser=<owner> grants=y commit=n ignore=y analyze=n constraints=y |
Importando estrutura e dados para owner já existente
Operação muito utilizada para replicação ou criação de novos ambientes, o import de estrutura e dados para um owner já existente consiste em apagar todos os objetos abaixo do owner do ambiente de destino e realizar o import.
Apagar toda a estrutura de um owner pode ser complicado às vezes, por isso muitos DBA’s preferem utilizar o comando drop user <usuario> cascade; para apagar o usuário e seus objetos de forma rápido e fácil.
Eu particularmente não gosto dessa solução, uma vez que não tenho o controle do que será apagado, nem muito menos um log dessa operação. Para isso, eu criei um script que executa essa tarefa e cria um novo script com os comandos para dropar todos os objetos do owner e registra um log com cada operação realizada (script em anexo no rodapé do post):
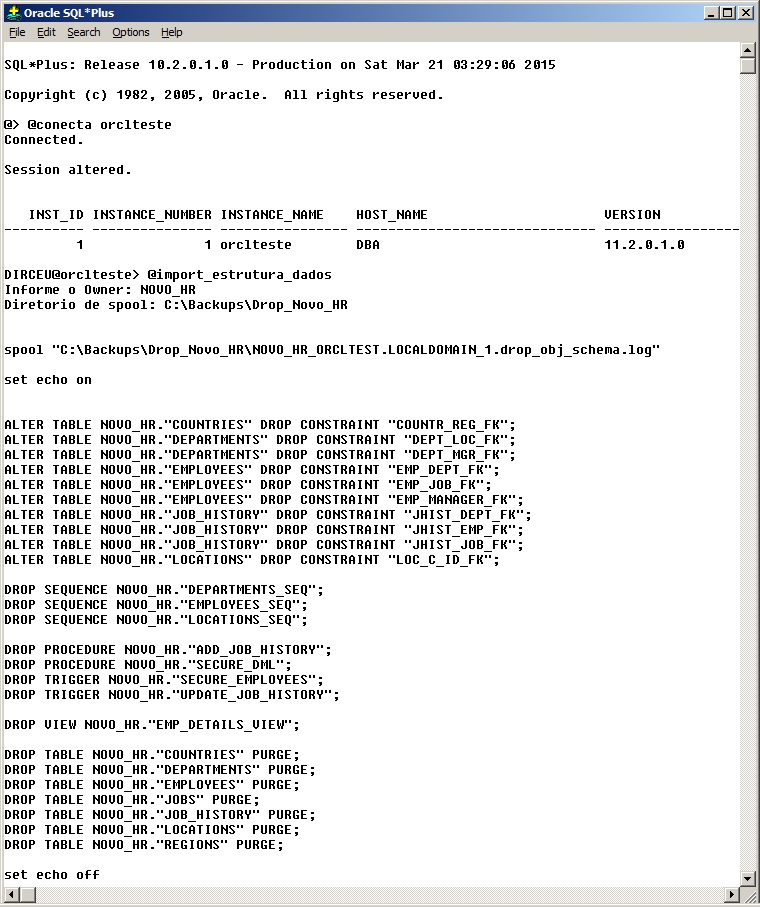
Após a execução do script gerado, apagando todos os objetos do owner, pode-se realizar o import normalmente, que ele irá recriar todos os objetos desse owner de acordo com o que existe no arquivo de dump. (Lembre-se de verificar o tamanho das tablespaces e datafiles, conforme citado acima)
|
1 2 |
# Como eu costumo utilizar - Crio um arquivo parfile.dat com o userid imp parfile="C:\parfile.dat" file=exp_<owner>_<instancia>.dmp buffer=409600000 log=imp_<owner>_<instancia>.dmp fromuser=<owner> touser=<owner> grants=n commit=n ignore=n analyze=n constraints=y |
Importando apenas dados para owner já existente
Essa é uma operação mais complexa que o dump de estrutura e dados e tem como objetivo atualizar os dados de um ambiente, sem alterar a sua estrutura no ambiente de destino. Para realizar isso, precisaremos apagar todos os dados das tabelas, desabilitar as contraints e triggers, apagar as sequences (script em anexo no rodapé do post).
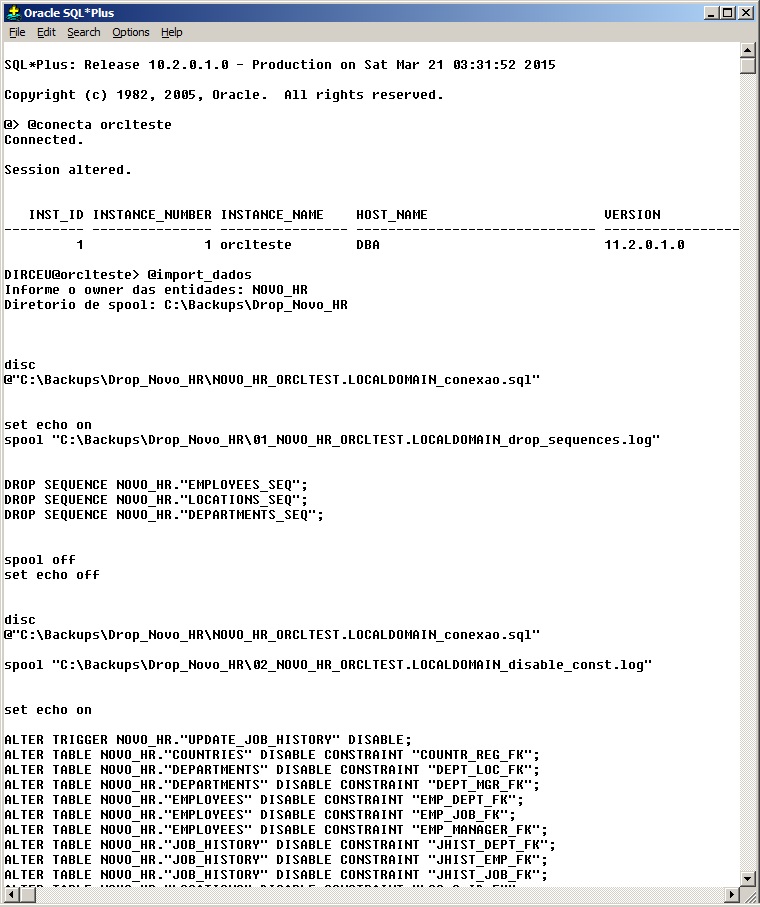
Como vocês sabem, caso existam novos objetos no ambiente de origem em que foi gerado o export dos dados, esses objetos serão criados no import. Por isso, precisaremos criar um script para apagar esses novos objetos que podem ser criados caso essa situação ocorra.
A forma mais fácil para isso, é utilizando o software Toad for Oracle, que permite uma comparação visual e geração de script para igualar os ambientes. Esse script deverá ser validado por você, de modo que ele trate apenas da remoção dos novos objetos criados (caso existam). Aqui não existe receita de bolo, pois cada ambiente e owner exigem scripts personalizados para cada situação.
Caso exista diferença entre objetos, o import de dados irá falhar. Você, como DBA, deverá alertar o solicitante que o import não será possível ou aplicar o script do Toad para igualar os ambientes, e após o import, aplicar o script do Toad para voltar as alterações e manter a estrutura do ambiente como estava antes.
|
1 2 |
# Como eu costumo utilizar - Crio um arquivo parfile.dat com o userid imp parfile="C:\parfile.dat" file=exp_<owner>_<instancia>.dmp buffer=409600000 log=imp_<owner>_<instancia>.dmp fromuser=<owner> touser=<owner> grants=n commit=n ignore=y analyze=n constraints=n |
Algumas dicas para o Import
- show parameter archive: Verifica o local onde os logs de transações (archivelog) são armazenados, para que você verifique se há espaço disponível para armazenar os logs que serão gerados pelo Import. Caso contrário, ele irá falhar.
- Verifique o tamanho da tablespace de UNDO para calcular se ela irá suportar as operações de UNDO que serão geradas pelo Import
- Verifique o tamanho do owner e o seu maior objeto. Ele não deve ser maior que a tablespace de undo
- Verifique se existem contraints desabilitadas antes do Import. Após o import, contraints podem ficar inválidas ou apresentar erros de inconsistência dos dados. Você precisa garantir que esses erros já existiam na base antes do Import.
- Verifique e compare o tamanho das tablespaces e datafiles de origem e destino, para garantir que os dados não irão estourar sua tablespace ou datafile na instância de destino.
- Os scripts com esse passo a passo estão disponíveis aqui.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
select sum(bytes)/1024/1024 || ' mb' from dba_segments where owner = 'HR'; select owner, sum(bytes)/1024/1024 || ' mb' from dba_segments where owner = 'HR' group by owner; select distinct tablespace_name from dba_segments where owner = 'HR' order by tablespace_name; @tablespace_tamanho HR @info_tablespace undo select owner, segment_name, segment_type, bytes/1024/1024 || ' MB' from dba_segments where bytes = ( select max(bytes) from dba_segments where owner = 'HR' and segment_type not like '%LOB%' ) and owner = 'HR'; select owner, segment_name, segment_type, bytes/1024/1024 || ' MB' from dba_segments where bytes = ( select max(bytes) from dba_segments where owner = 'HR' and segment_type like '%LOB%' ) and owner = 'HR'; show parameter archive @free_asm select * from dba_constraints where status = 'DISABLED' and owner = 'HR'; select * from v$instance; select * from gv$instance; |
Scripts utilizados para realizar o import de estrutura e dados e somente dados
Para informações técnicas mais detalhadas, favor verificar no Site Oficial da Oracle – Export e Import.

Boa noite!
Preciso criar as tabelas abaixo, porém, com usuários distintos!
COM USER FOCVS
create table FOCVS.SIS_SYNC_LOGITEM
(
ID_SYNC_LOGITEM VARCHAR2(50),
ID_LICENCA INTEGER default 1,
ID_EXECUCAO VARCHAR2(50),
)
COM USER FOCVS01
create table FOCVS.SIS_SYNC_LOGITEM
(
ID_SYNC_LOGITEM VARCHAR2(50),
ID_LICENCA INTEGER default 1,
ID_EXECUCAO VARCHAR2(50),
)
Como faço isso?
Por exemplo:
Tenho um dump inteiro com OWNER FOCVS e quero criar um ambiente de TESTE com este dump para o USER FOCVS01, como faço isso?
Obrigado!
Muito bom mesmo. Vou ficar voltando sempre pra ver se aparece algo nos mesmos moldes para o impdp/expdp que, apesar de serem bem parecidos, têm suas peculiaridades. Antes que algum visitante me pergunte porque eu mesmo não faço, é que eu não tenho um blog e muito menos essa didática que encontrei aqui. Sucesso sempre!
Antônio, está no planos criar um parecido com esse, sobre o Datapump.. Aguarde.. rs
Olá,
Sou novata como DBA e estou com uma dúvida, após realizar o import posso apagar o arquivo .dmp do caminho informado na hora do import??
Preciso apagar esse arquivo pois é muito grande para ficar armazenado do servidor.
Grata.
Maiara Gradim
Oi Maiara, boa tarde.
Primeiramente, obrigado pela visita. 🙂
Após realizar o import, pode apagar o arquivo de dump sim, sem problemas.
Boa tarde Dirceu,
Realizei os passos mencionados acima por você, porém ao realizar o import tenho erros de “restrição violada”.
Sabe me dizer como corrigir? Utilizei o arquivo disponível (import_estrutura_dados).
Atenciosamente.
Maiara, você quer fazer import de dados apenas ou estrutura e dados?
Não entendi como eu informo a senha no arquivo. Obrigado..
Ulisses, sua dúvida é no export ou import ?
Estou começando a utilizar o oracle fazendo dump mas estou tendo problema no banco de destino onde ao salvar um registro ele me da erro de “registro já existente”, pelo que fui informado é que as sequences do banco 1 não foi gerado no exp e importado pelo imp no banco 2 . Há alguma forma de não ocorrer esses erros de sequence ao importar?
Patrick,
Bom dia e obrigado pela visita.
Se você estiver importando o owner inteiro e todos os seus objetos para outro servidor/owner, você pode excluir todos os objetos do destino e deixar que o import recria os objetos (lembre-se de salvar as permissões na origem para aplicar no destino). Desta forma, acredito que você não terá esse problema.
Dá uma olhada neste post, pois tem um script (import_estrutura_dados) que já faz tudo isso pra você.
Se ainda tiver com dúvidas, é só falar.
Estou usando 1 servidor com 2 instancias uma prd e outra sml .. os bancos tem mesma estrutura.. um pra produção e outro pra simulação .. o owner é o mesmo nos dois bancos..
Esse seu script é pra windows? Deve ser executado somente m sqlplus ou pode ser no tools?
Patrick, os scripts foram desenvolvidos para o sqlplus no Windows, mas funcionam em qualquer ambiente, desde que seja utilizado o sqlplus. O que seria o tools ?
seria o SQL tools, o gerenciador de conexões ..
Muito bom!